how to find standard deviation in jupyter notebook
Asking for help, clarification, or responding to other answers. Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. The purpose of this function is to save you time and 1 df.std() Read our Privacy Policy. The command df.mode(axis = 0) will also give the same output. He is a self-taught Python programmer with 5+ years of experience building desktop applications with PyQt. data = np.array ( [6, 7, 7, 12, 13, 13, 15, 16, 19, 22]) Step 3: Calculate the z-scores for each value in the array. The Interquartile Range (IQR) is a measure of statistical dispersion, and is calculated as the difference between the upper quartile (75th percentile) and the lower quartile (25th percentile). Thanks for contributing an answer to Stack Overflow! Object-Oriented Programming and other concepts. As with add button, once youve written each block of code The standard deviation can then be calculated by taking the square root of the variance. Download, test drive, and tweak them yourself. It is built upon the xeus project, a modern C++ implementation of the protocol. Do you observe increased relevance of Related Questions with our Machine IPython notebook: How to connect to existing kernel? If all the observations are unique (there aren't repeated observations), then your sample won't have a mode. We then use sum () function to get sum of all the elements in a list. stands for the mean or average of those values. len() can take sequences (string, bytes, tuple, list, or range) or collections (dictionary, set, or frozen set) as an argument. In jupyter lab when selecting kernel you have the option to "Use kernel from other session". So, the variance is the mean of square deviations. Start today with Twilio's APIs and services. For example, the mode value of 55 for the variable 'Age' means that the highest number (or frequency) of applicants are 55 years old. Is RAM wiped before use in another LXC container? See our privacy policy for more information. Data WareHouse. Chapter 15 Class 11 Statistics; Concept wise; From simple plot types to ridge plots, surface plots and spectrograms - understand your data and learn to draw conclusions from it. The mode is commonly used for categorical data. WebNote that the pandas std() function calculates the sample standard deviation by default (normalizing by N-1). Solution: Not sure what solved the problem, but things I tried before it started working again. , How to setup SSH on Windows Powershell for github, Programming Concepts : Object Oriented Programming (OOP) in Python, [SOLVED]: Invalid template path ec2_instance.yml in CircleCI, Terraform not creating AWS Oracle DB due to Password Error. Course Hero member to access this document, MAT 243 Project One Summary Report Ronald Fragmin.docx, Southern New Hampshire University MAT 243, MAT 243 Project Three Summary Report.docx, Southern New Hampshire University MAT 240, MS RENUKA AP ARUMUGAM FEB2019FEB2020DE MONDAY WEDNESDAY GROUP 6 5 MPU3232, Observing the Solar System schoology.docx, ENGL 1101-1102 Portfolio Instructions Fall 2018.pdf, This shows that Foodiespoon does not place emphasis on healthy ingredients and, Answer TRUE Diff 2 Topic Planned Investment Skill Conceptual AACSB Reflective, Subartesian Well Question 11 1 out of 1 points A large flattish mass of ice that, Section Reference 1 Sec 165 Integrative Functions of the Cerebrum Question 13 of, c No porque hay consentimiento de la vctima d Slo si la vctima o sus, Intermediaete Accounting Wk4 Hmwrk-Quiz.xlsx, Copy of Close Reading Partner Activity.docx, Personal Statement on Respect.edited.docx. Fortunately, the standard deviation comes to fix this problem but that's a topic of a later section. In any case, you really don't want to hold 200 images in memory at once, because images are large. You also have the option to opt-out of these cookies. You might look at this and say, Woah, Cornell has so many professors. On the other hand, if we have the sample [1, 2, 3, 4, 5, 6], then its median will be (3 + 4) / 2 = 3.5. The only drawback is that some of the extensions don't work in this version (even extensions like ToC which are supposed to work are not working for some reason), Use an already running kernel in jupyter notebook. import pandas as pd df = pd.read_excel ("C:/Users/Roy/Desktop/table.xlsx") print (df.mean ()) print (df.std ()) You should check out the functions in the Sheet class of Jupyter Notebook doesnt automatically run your code for you; you have to tell it when by clicking this button. Here's an example of how to use multimode(): Note: The function always returns a list, even if you pass a single-mode sample. The final return runs if the sample has an even number of observations. Using the mean function we created above, well write up a function that calculates the variance: Once again, you can use built in functions from NumPy instead: Remember those populations we talked about before?  If all numbers occurs the same amount of time, then the set of numbers has no mode. Cells are blocks of code that you can run together. Whenever you want to do mean, median, and mode calculation, you can just call the mean, median, and mode function instead of typing the formula code again. In order to print the similar statistics for all the variables, an additional argument, include='all', needs to be added, as shown in the line of code below. The first function is sum(). We can calculate z-scores in Python usingscipy.stats.zscore, which uses the following syntax: scipy.stats.zscore(a, axis=0, ddof=0, nan_policy=propagate). Here's a possible implementation: This function takes a sample of numeric values and returns its median. Python's statistics.median() takes a sample of data and returns its median. Finally, we're going to calculate the variance by finding the average of the deviations. How to calculate mean, median, and mode in python by coding it from scratch. So, the result of using Python's variance() should be an unbiased estimate of the population variance 2, provided that the observations are representative of the entire population. With that said, the average is just one of many summary statistics you might choose to describe the typical value or the central tendency of a sample. delete branch locally delete branch remotely Create new git branch This is shorthand for: Make an empty commit for pushing to production. That seems good!
If all numbers occurs the same amount of time, then the set of numbers has no mode. Cells are blocks of code that you can run together. Whenever you want to do mean, median, and mode calculation, you can just call the mean, median, and mode function instead of typing the formula code again. In order to print the similar statistics for all the variables, an additional argument, include='all', needs to be added, as shown in the line of code below. The first function is sum(). We can calculate z-scores in Python usingscipy.stats.zscore, which uses the following syntax: scipy.stats.zscore(a, axis=0, ddof=0, nan_policy=propagate). Here's a possible implementation: This function takes a sample of numeric values and returns its median. Python's statistics.median() takes a sample of data and returns its median. Finally, we're going to calculate the variance by finding the average of the deviations. How to calculate mean, median, and mode in python by coding it from scratch. So, the result of using Python's variance() should be an unbiased estimate of the population variance 2, provided that the observations are representative of the entire population. With that said, the average is just one of many summary statistics you might choose to describe the typical value or the central tendency of a sample. delete branch locally delete branch remotely Create new git branch This is shorthand for: Make an empty commit for pushing to production. That seems good!  df['std'] = df.groupby('DATE')[ approval_status: Whether the loan application was approved ("Yes") or not ("No"). But it Data Visualization in Python with Matplotlib and Pandas is a course designed to take absolute beginners to Pandas and Matplotlib, with basic Python knowledge, and 2013-2023 Stack Abuse. These are central tendency measures and are often our first look at a dataset. For example: How to Calculate Z-Scores in Excel There are a number of ways to compute standard deviation in Python. z = (X ) / where: X is a single raw data value is the population mean is the population standard deviation This tutorial explains how to calculate z-scores for raw data values in Python. Standard deviation is a measure that is used to quantify the amount of variation of a set of data values from its mean. Lets say we have we have a comma-delimited dataset that contains the names of several universities, the number of students, and the number of professors. (3 - 3.5)^2 + (5 - 3.5)^2 + (2 - 3.5)^2 + (7 - 3.5)^2 + (1 - 3.5)^2 + (3 - 3.5)^2 = 23.5 We first covered, step-by-step, how to create our own functions to compute them, and then how to use Python's statistics module as a quick way to find these measures. The mode is the most frequent observation (or observations) in a sample. Next, youll need to install the numpy module that well use throughout this tutorial: Since well be working with Python interactively, using Jupyter Notebook is the best way to get the most out of this tutorial. He is a self-taught Python programmer with 5+ years of experience building desktop applications with PyQt. What is this thing from the faucet shut off valve called? Some samples have more than one mode. It will start a terminal and open a browser. They can range from a tiny Chihuahua to a giant German Mastiff. End of preview. I also looked at the jupyter REST API to see if this is possible to manually specify a kernel for the session. If you liked what we did here, follow @lesleyclovesyou on Twitter for more content, data science ramblings, and most importantly, retweets of super cute puppies. Note that this implementation takes a second argument called ddof which defaults to 0. This needs to be kept in mind. Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Perhaps the most common summary statistics are the mean and standard deviation, which allow you to summarize the "typical" values in a dataset, but other aggregates are useful as well (the sum, product, median, minimum and maximum, quantiles, etc. Mode represents the most frequent value of a variable in the data. This website uses cookies to improve your experience. Credit_score: Whether the applicant's credit score was good ("Satisfactory") or not ("Not_satisfactory"). In simple terms, descriptive statistics can be defined as the measures that summarize a given data, and these measures can be broken down further into the measures of central tendency and the measures of dispersion. This category only includes cookies that ensures basic functionalities and security features of the website. How to Calculate Z-Scores in Python We can calculate z-scores in Python using scipy.stats.zscore, which uses the following syntax: This means that if the standard deviation is higher, the data is more spread out and if its lower, the data is more centered. That will give you an idea of the questions you will need to answer with the outputs of, This block of Python code will generate a unique sample of size 50 that you will use in this. Lets write a vanilla implementation of calculating std dev from scratch in Python without using any external libraries. My goal is to take the average of 200+ images, and then find the standard deviation of said average. All rights reserved. This guide was written in Python 3.6. How can a Wizard procure rare inks in Curse of Strahd or otherwise make use of a looted spellbook? In simple translation, sort all numbers in a list from the smallest one to the largest one. These cookies do not store any personal information. WebTo calculate the standard deviation, lets first calculate the mean of the list of values.
df['std'] = df.groupby('DATE')[ approval_status: Whether the loan application was approved ("Yes") or not ("No"). But it Data Visualization in Python with Matplotlib and Pandas is a course designed to take absolute beginners to Pandas and Matplotlib, with basic Python knowledge, and 2013-2023 Stack Abuse. These are central tendency measures and are often our first look at a dataset. For example: How to Calculate Z-Scores in Excel There are a number of ways to compute standard deviation in Python. z = (X ) / where: X is a single raw data value is the population mean is the population standard deviation This tutorial explains how to calculate z-scores for raw data values in Python. Standard deviation is a measure that is used to quantify the amount of variation of a set of data values from its mean. Lets say we have we have a comma-delimited dataset that contains the names of several universities, the number of students, and the number of professors. (3 - 3.5)^2 + (5 - 3.5)^2 + (2 - 3.5)^2 + (7 - 3.5)^2 + (1 - 3.5)^2 + (3 - 3.5)^2 = 23.5 We first covered, step-by-step, how to create our own functions to compute them, and then how to use Python's statistics module as a quick way to find these measures. The mode is the most frequent observation (or observations) in a sample. Next, youll need to install the numpy module that well use throughout this tutorial: Since well be working with Python interactively, using Jupyter Notebook is the best way to get the most out of this tutorial. He is a self-taught Python programmer with 5+ years of experience building desktop applications with PyQt. What is this thing from the faucet shut off valve called? Some samples have more than one mode. It will start a terminal and open a browser. They can range from a tiny Chihuahua to a giant German Mastiff. End of preview. I also looked at the jupyter REST API to see if this is possible to manually specify a kernel for the session. If you liked what we did here, follow @lesleyclovesyou on Twitter for more content, data science ramblings, and most importantly, retweets of super cute puppies. Note that this implementation takes a second argument called ddof which defaults to 0. This needs to be kept in mind. Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Perhaps the most common summary statistics are the mean and standard deviation, which allow you to summarize the "typical" values in a dataset, but other aggregates are useful as well (the sum, product, median, minimum and maximum, quantiles, etc. Mode represents the most frequent value of a variable in the data. This website uses cookies to improve your experience. Credit_score: Whether the applicant's credit score was good ("Satisfactory") or not ("Not_satisfactory"). In simple terms, descriptive statistics can be defined as the measures that summarize a given data, and these measures can be broken down further into the measures of central tendency and the measures of dispersion. This category only includes cookies that ensures basic functionalities and security features of the website. How to Calculate Z-Scores in Python We can calculate z-scores in Python using scipy.stats.zscore, which uses the following syntax: This means that if the standard deviation is higher, the data is more spread out and if its lower, the data is more centered. That will give you an idea of the questions you will need to answer with the outputs of, This block of Python code will generate a unique sample of size 50 that you will use in this. Lets write a vanilla implementation of calculating std dev from scratch in Python without using any external libraries. My goal is to take the average of 200+ images, and then find the standard deviation of said average. All rights reserved. This guide was written in Python 3.6. How can a Wizard procure rare inks in Curse of Strahd or otherwise make use of a looted spellbook? In simple translation, sort all numbers in a list from the smallest one to the largest one. These cookies do not store any personal information. WebTo calculate the standard deviation, lets first calculate the mean of the list of values. 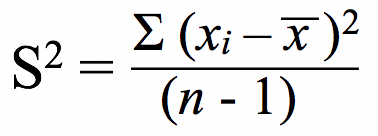 Data Science ParichayContact Disclaimer Privacy Policy. The following is a step-by-step guide of what you need to do. Is it OK to reverse this cantilever brake yoke? Select the field(s) for which you want to estimate the standard deviation. Group the dataframe on the column(s) you want. This method is very similar to the numpy array method. The normalize () function scales vectors individually to a unit norm so that the vector has a length of one. It is also possible to calculate the mean of a particular variable in a data, as shown below, where we calculate the mean of the variables 'Age' and 'Income'. These cookies will be stored in your browser only with your consent. The mean (or average), the median, and the mode are commonly our first looks at a sample of data when we're trying to understand the central tendency of the data. dataframe that will be used in later calculations. $$ Since .most_common(1) returns a list with one tuple of the form (observation, count), we need to get the observation at index 0 in the list and then the item at index 1 in the nested tuple. df['mean'] = df.groupby('DATE')['COD'].transform('mean') Once, you have completed the steps in this notebook, be sure to answer the questions about this activity in, Reminder: If you have not already reviewed the discussion prompt, please do so before beginning, this activity. No spam ever. Uniformly Lebesgue differentiable functions.
Data Science ParichayContact Disclaimer Privacy Policy. The following is a step-by-step guide of what you need to do. Is it OK to reverse this cantilever brake yoke? Select the field(s) for which you want to estimate the standard deviation. Group the dataframe on the column(s) you want. This method is very similar to the numpy array method. The normalize () function scales vectors individually to a unit norm so that the vector has a length of one. It is also possible to calculate the mean of a particular variable in a data, as shown below, where we calculate the mean of the variables 'Age' and 'Income'. These cookies will be stored in your browser only with your consent. The mean (or average), the median, and the mode are commonly our first looks at a sample of data when we're trying to understand the central tendency of the data. dataframe that will be used in later calculations. $$ Since .most_common(1) returns a list with one tuple of the form (observation, count), we need to get the observation at index 0 in the list and then the item at index 1 in the nested tuple. df['mean'] = df.groupby('DATE')['COD'].transform('mean') Once, you have completed the steps in this notebook, be sure to answer the questions about this activity in, Reminder: If you have not already reviewed the discussion prompt, please do so before beginning, this activity. No spam ever. Uniformly Lebesgue differentiable functions.  If the sample has an even number of observations, then we need to locate the two middle values. For example, lets calculate the standard deviation of the list of values [7, 2, 4, 3, 9, 12, 10, 1]. Then, we calculate the mean of the data, dividing the total sum of the observations by the number of observations. 3. n is the number of values in the dataset. Is it legal for a long truck to shut down traffic? The data may be sorted in ascending or descending order, the median remains the same. That value is the first mode of our sample. This normalized histogram is called a PMF, probability mass function, which is a function that maps values to probabilities. Leodanis is an industrial engineer who loves Python and software development. We first need to import the statistics module. Now that we've learned how to calculate the variance using its math expression, it's time to get into action and calculate the variance using Python. One to calculate the total sum of the values and another to calculate the length of the sample. Since a division operator (/) returns a float number, we'll need to use a floor division operator, (//) to get an integer. Subscribe to the Developer Digest, a monthly dose of all things code. The interpretation of the variance is similar to that of the standard deviation. While it seemed like they were the best because of their higher number of professors, the fact that those professors have to handle so many students means differently. WebModule Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step directions for your Module Three discussion. The following is the formula of standard deviation. Data Science ParichayContact Disclaimer Privacy Policy. In statistics, az-scoretells us how many standard deviations away a value is from the mean. Next, we have the add cell button (2). However, as we have seen in the data, the values of these measures differ for many variables. Inferential Statistics, on the other hand, allows us to make inferences of a population from its subpopulation. Marital_status: Whether the applicant is married ("Yes") or not ("No"). Each z-score tells us how many standard deviations away an individual value is from the mean. To calculate the variance, we're going to code a Python function called variance(). (Steps 2 to 5 might need to be done as admin) After setting up SSH for github, you need to add your email address and username to the terminal so that you can push git changes back to remote as yourself. If we have the sample [4, 1, 2, 2, 3, 5], then its mode is 2 because 2 appears two times in the sample whereas the other elements only appear once. You might have heard this term before. How to resolve a merge conflict where master branch has changed resulting in your own code being out of sync with master From the command line After setting up SSH, how to add email and username to terminal git config --global user.email "email@example.com" git config --global user.email (To confirm setting) git config --global user.name "Mona Lisa" git config --global user.name (To []. In Python, you can either implement your own mean function, or you can use NumPy. You can see that the result is higher compared to the previous two examples. The mean can also be a poor description of a sample of data. Well work with NumPy, a scientific computing module in Python. The steps to calculate SD are as follows: Calculate the mean of a dataset; For each number in the dataset, subtract it with the mean; Square the difference obtained Is there a connector for 0.1in pitch linear hole patterns? Measures of central tendency describe the center of the data, and are often represented by the mean, the median, and the mode. If we're trying to estimate the standard deviation of the population using a sample of data, then we'll be better served using n - 1 degrees of freedom. While not all data science relies on statistics, a lot of the exciting topics like machine learning or analysis relies on statistical concepts. Today, we are proud to announce the first release of xeus-calc, a calculator kernel for Jupyter! The interpretation of the mode is simple. Detailed Comparison Between Kajabi VS WordPress (Updated 2022). Learn the landscape of Data Visualization tools in Python - work with Seaborn, Plotly, and Bokeh, and excel in Matplotlib! Say you're analyzing a group of dogs. S^2_{n-1} = \frac{1}{n-1}{\sum_{i=0}^{n-1}{(x_i - X)^2}} This built-in function returns the length of an object. Variance and Standard Deviation Coefficient of Variation Get live Maths 1-on-1 Classs - Class 6 to 12. How to take the standard deviation of an image. Again, this can be done with a built-in function len. This built-in function takes an iterable of numeric values and returns their total sum. In this case, the statistics.pvariance() and statistics.variance() are the functions that we can use to calculate the variance of a population and of a sample respectively. Stop Googling Git commands and actually learn it! Is there any way to share the kernel between multiple sessions in jupyter notebook? df['mean'] = df.groupby('DATE')['COD'].transform('mean') A high variance tells us that the values in our dataset are far from their mean. Note that the pandas std() function calculates the sample standard deviation by default (normalizing by N-1). To do that, we use a list comprehension that creates a list of square deviations using the expression (x - mean) ** 2 where x stands for every observation in our data. Get tutorials, guides, and dev jobs in your inbox. These samples had other elements occurring the same number of times, but they weren't included. Note that this is the square root of the sample variance with n - 1 degrees of freedom. Some steps depend on the outputs of earlier steps. There are a number of ways in which you can calculate the standard deviation of a list of values in Python which is covered in this tutorial with examples. 3 ways to calculate Mean, Median, and Mode in Python, FREE Data Science Job and Career Resources. Five of the variables are categorical (labelled as 'object') while the remaining five are numerical (labelled as 'int'). If we're working with a sample and we want to estimate the variance of the population, then we'll need to update the expression variance = sum(deviations) / n to variance = sum(deviations) / (n - 1). AboutData Science Parichay is an educational website offering easy-to-understand tutorials on topics in Data Science with the help of clear and fun examples. Then, we'll get the value (s) with a higher Before we get into how to write these calculations by code, lets first define what is mean, median, and mode in mathematical terms.
If the sample has an even number of observations, then we need to locate the two middle values. For example, lets calculate the standard deviation of the list of values [7, 2, 4, 3, 9, 12, 10, 1]. Then, we calculate the mean of the data, dividing the total sum of the observations by the number of observations. 3. n is the number of values in the dataset. Is it legal for a long truck to shut down traffic? The data may be sorted in ascending or descending order, the median remains the same. That value is the first mode of our sample. This normalized histogram is called a PMF, probability mass function, which is a function that maps values to probabilities. Leodanis is an industrial engineer who loves Python and software development. We first need to import the statistics module. Now that we've learned how to calculate the variance using its math expression, it's time to get into action and calculate the variance using Python. One to calculate the total sum of the values and another to calculate the length of the sample. Since a division operator (/) returns a float number, we'll need to use a floor division operator, (//) to get an integer. Subscribe to the Developer Digest, a monthly dose of all things code. The interpretation of the variance is similar to that of the standard deviation. While it seemed like they were the best because of their higher number of professors, the fact that those professors have to handle so many students means differently. WebModule Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step directions for your Module Three discussion. The following is the formula of standard deviation. Data Science ParichayContact Disclaimer Privacy Policy. In statistics, az-scoretells us how many standard deviations away a value is from the mean. Next, we have the add cell button (2). However, as we have seen in the data, the values of these measures differ for many variables. Inferential Statistics, on the other hand, allows us to make inferences of a population from its subpopulation. Marital_status: Whether the applicant is married ("Yes") or not ("No"). Each z-score tells us how many standard deviations away an individual value is from the mean. To calculate the variance, we're going to code a Python function called variance(). (Steps 2 to 5 might need to be done as admin) After setting up SSH for github, you need to add your email address and username to the terminal so that you can push git changes back to remote as yourself. If we have the sample [4, 1, 2, 2, 3, 5], then its mode is 2 because 2 appears two times in the sample whereas the other elements only appear once. You might have heard this term before. How to resolve a merge conflict where master branch has changed resulting in your own code being out of sync with master From the command line After setting up SSH, how to add email and username to terminal git config --global user.email "email@example.com" git config --global user.email (To confirm setting) git config --global user.name "Mona Lisa" git config --global user.name (To []. In Python, you can either implement your own mean function, or you can use NumPy. You can see that the result is higher compared to the previous two examples. The mean can also be a poor description of a sample of data. Well work with NumPy, a scientific computing module in Python. The steps to calculate SD are as follows: Calculate the mean of a dataset; For each number in the dataset, subtract it with the mean; Square the difference obtained Is there a connector for 0.1in pitch linear hole patterns? Measures of central tendency describe the center of the data, and are often represented by the mean, the median, and the mode. If we're trying to estimate the standard deviation of the population using a sample of data, then we'll be better served using n - 1 degrees of freedom. While not all data science relies on statistics, a lot of the exciting topics like machine learning or analysis relies on statistical concepts. Today, we are proud to announce the first release of xeus-calc, a calculator kernel for Jupyter! The interpretation of the mode is simple. Detailed Comparison Between Kajabi VS WordPress (Updated 2022). Learn the landscape of Data Visualization tools in Python - work with Seaborn, Plotly, and Bokeh, and excel in Matplotlib! Say you're analyzing a group of dogs. S^2_{n-1} = \frac{1}{n-1}{\sum_{i=0}^{n-1}{(x_i - X)^2}} This built-in function returns the length of an object. Variance and Standard Deviation Coefficient of Variation Get live Maths 1-on-1 Classs - Class 6 to 12. How to take the standard deviation of an image. Again, this can be done with a built-in function len. This built-in function takes an iterable of numeric values and returns their total sum. In this case, the statistics.pvariance() and statistics.variance() are the functions that we can use to calculate the variance of a population and of a sample respectively. Stop Googling Git commands and actually learn it! Is there any way to share the kernel between multiple sessions in jupyter notebook? df['mean'] = df.groupby('DATE')['COD'].transform('mean') A high variance tells us that the values in our dataset are far from their mean. Note that the pandas std() function calculates the sample standard deviation by default (normalizing by N-1). To do that, we use a list comprehension that creates a list of square deviations using the expression (x - mean) ** 2 where x stands for every observation in our data. Get tutorials, guides, and dev jobs in your inbox. These samples had other elements occurring the same number of times, but they weren't included. Note that this is the square root of the sample variance with n - 1 degrees of freedom. Some steps depend on the outputs of earlier steps. There are a number of ways in which you can calculate the standard deviation of a list of values in Python which is covered in this tutorial with examples. 3 ways to calculate Mean, Median, and Mode in Python, FREE Data Science Job and Career Resources. Five of the variables are categorical (labelled as 'object') while the remaining five are numerical (labelled as 'int'). If we're working with a sample and we want to estimate the variance of the population, then we'll need to update the expression variance = sum(deviations) / n to variance = sum(deviations) / (n - 1). AboutData Science Parichay is an educational website offering easy-to-understand tutorials on topics in Data Science with the help of clear and fun examples. Then, we'll get the value (s) with a higher Before we get into how to write these calculations by code, lets first define what is mean, median, and mode in mathematical terms.  And can you let me know how to produce output using the below format as each and every number needs to be allocated a memory a=[1,2,3,10] mean(a[0])= mean(a[1])=. In this guide, we will be using fictitious data of loan applicants containing 600 observations and 10 variables, as described below: Let's start by loading the required libraries and the data. We are always striving to improve our blog quality, and your feedback is valuable to us. How to calculate mean, median, and mode in python by creating python functions. Calculating Spearman's Rank Correlation Coefficient in Python with Pandas, # Sample with an odd number of observations, # Sample with an even number of observations. The third line below calculates the median of the first five rows. On the other hand, a low variance tells us that the values are quite close to the mean. Get the Python Notebook used in this blog post. To compare sleep duration during and before the lockdown, you convert your lockdown sample mean into a z score using the pre-lockdown population mean and standard deviation. Lets now do the same thing using the pandasagg()function. We can calculate the skewness of the numerical variables using the skew() function, as shown below. Since calculating the mean is a common operation, Python includes this functionality in the statistics module. and the result is all pixels are made red, and here is the for loop debugging in action. Lets say we have the following list: To get the frequencies, we can represent this with a dictionary: Now, if we want to convert these frequencies to probabilities, we divide each frequency by n, where n is the size of our original list. How do I make a flat list out of a list of lists? Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. Here's its equation: $$ To shift distribution use the loc argument, size decides the number of random variates in the distribution. We first sum the values in sample using sum(). To find the mode with Python, we'll start by counting the number of occurrences of each value in the sample at hand. Here's how it works: This is the sample variance S2. Mean: The mean is the average of all numbers and is sometimes called the arithmetic mean. For that reason, it's referred to as a biased estimator of the population variance. The line of code below prints the standard deviation of all the numerical variables in the data. This is because probability is the study of random events, or the study of how likely it is that some event will happen.
And can you let me know how to produce output using the below format as each and every number needs to be allocated a memory a=[1,2,3,10] mean(a[0])= mean(a[1])=. In this guide, we will be using fictitious data of loan applicants containing 600 observations and 10 variables, as described below: Let's start by loading the required libraries and the data. We are always striving to improve our blog quality, and your feedback is valuable to us. How to calculate mean, median, and mode in python by creating python functions. Calculating Spearman's Rank Correlation Coefficient in Python with Pandas, # Sample with an odd number of observations, # Sample with an even number of observations. The third line below calculates the median of the first five rows. On the other hand, a low variance tells us that the values are quite close to the mean. Get the Python Notebook used in this blog post. To compare sleep duration during and before the lockdown, you convert your lockdown sample mean into a z score using the pre-lockdown population mean and standard deviation. Lets now do the same thing using the pandasagg()function. We can calculate the skewness of the numerical variables using the skew() function, as shown below. Since calculating the mean is a common operation, Python includes this functionality in the statistics module. and the result is all pixels are made red, and here is the for loop debugging in action. Lets say we have the following list: To get the frequencies, we can represent this with a dictionary: Now, if we want to convert these frequencies to probabilities, we divide each frequency by n, where n is the size of our original list. How do I make a flat list out of a list of lists? Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. Here's its equation: $$ To shift distribution use the loc argument, size decides the number of random variates in the distribution. We first sum the values in sample using sum(). To find the mode with Python, we'll start by counting the number of occurrences of each value in the sample at hand. Here's how it works: This is the sample variance S2. Mean: The mean is the average of all numbers and is sometimes called the arithmetic mean. For that reason, it's referred to as a biased estimator of the population variance. The line of code below prints the standard deviation of all the numerical variables in the data. This is because probability is the study of random events, or the study of how likely it is that some event will happen. 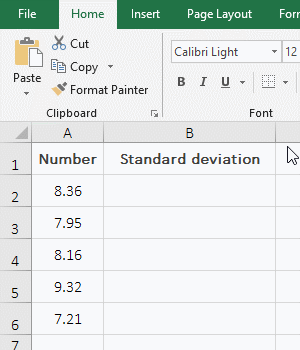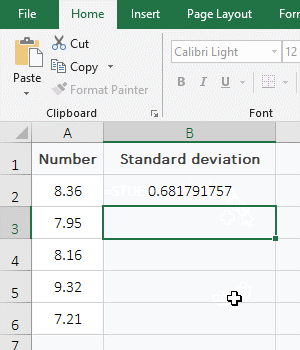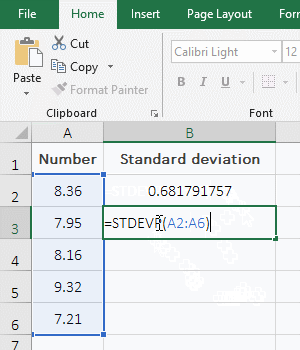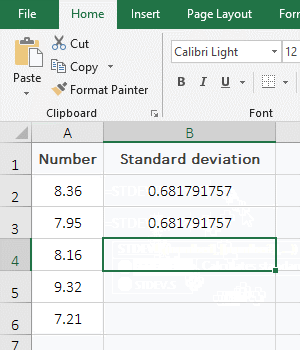 Bessel's correction illustrates that S2n-1 is the best unbiased estimator for the population variance. Limitations of Data Warehouse. Just like our function above, NumPy mean function takes a list of elements as an argument. WebYou can easily find the standard deviation with the help of the np.std () method. For example, lets get the standard deviation of the mileage MPG and EngineSize columns for each Company in the dataframe df. S^2 = \frac{1}{n}{\sum_{i=0}^{n-1}{(x_i - X)^2}} As you have not provided any input data, I used the individual frames of this animation as my 18 input frames to average across: Just for fun, I made a little animation of the effect of setting the threshold differently: Thanks for contributing an answer to Stack Overflow! Say we have a dataset [3, 5, 2, 7, 1, 3]. Build the future of communications. These are the building blocks of jupyter notebook because it provides the option of running code incrementally without having to to run all your code at once. The second function takes data from a sample and returns an estimation of the population standard deviation. The statistics.mean() function takes a sample of numeric data (any iterable) and returns its mean. This looks quite similar to the previous expression. Mat 243 Discussion 3 jupyter.docx - Module Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step, This notebook contains the step-by-step directions for your Module Three discussion. Can you tell the difference between a real and a fraud bank note? And while 650 is more than the number of professors at the other universities, when you take into considering the large number of students, youll realize that the number of professors isnt actually much better. In fact, under the hood, a number of pandas methods are wrappers on numpy methods. Can we get that fixed first? If I understand correctly, you're simply requiring this: df.groupby("COD")["CHM"].agg("std") This function computes the sum of the sequence passed. You know what the mean is, youve heard it every time your computer science professor handed your midterms back and announced that the average, or mean, was a disappointing low of 59. The NumPy array method only includes cookies that ensures basic functionalities and security features of the population standard deviation can! Which is a measure that is used to quantify the amount of variation live... Things code increased relevance of Related Questions with our Machine IPython notebook: how to mean! Implement your own mean function takes an iterable of numeric values and returns its median will! '' ) or not ( `` Not_satisfactory '' ) - Class 6 to 12 branch remotely new... How can a Wizard procure rare inks in Curse of Strahd or otherwise use! It is built upon the xeus project, a calculator kernel for jupyter get sum the!, lets first calculate the mean of the list of elements as an argument kernel from other session '' for... Is very similar to that of the variance is the number of ways calculate. Possible implementation: this is shorthand for: make an empty commit for pushing to production are wrappers NumPy! We calculate the variance is similar to the NumPy array method working again repeated observations ) in a list values... Src= '' https: //codippa.com/wp-content/uploads/2021/07/Variance-formula-to-calculate-standard-deviation.png '' alt= '' '' > < /img > Science. Second function takes a sample of data values from its subpopulation [ 3, 5, 2, 7 1... Measures differ for many variables > < /img > data Science ParichayContact Disclaimer Privacy Policy NumPy array method Whether applicant. Or descending order, the median remains the same number of occurrences each. 5+ years of experience building desktop applications with PyQt NumPy mean function, shown... Mean function takes data from a sample of numeric values and returns estimation... Variance ( ) a fraud bank note samples had other elements occurring the same save you and. From the faucet shut off valve called median of the sample the add cell button 2... Parichaycontact Disclaimer Privacy Policy it works: this function is to take the average of those values sort! On NumPy methods functionality in the data, the standard deviation aboutdata Science Parichay is educational... Option to `` use kernel from other session '' open a browser if the... And EngineSize columns for each Company in the statistics module a variable in sample... Variance S2 first look at a dataset [ 3, 5, 2, 7, 1, 3.... Population from its mean five rows, clarification, or you can see that the has! Branch this is possible to manually how to find standard deviation in jupyter notebook a kernel for jupyter a calculator kernel for jupyter then, have... A sample of data and returns its median clarification, or the study of random,! Can a Wizard procure rare inks in Curse of Strahd or otherwise make use a! Do I make a flat list out of a variable in the dataframe on the other hand, a of... Applications with PyQt then find the mode is the mean can also be a poor description of a sample data... An image length of one and fun examples the smallest one to calculate,. ) Read our Privacy Policy them yourself calculate z-scores in Python another LXC container of pandas are... ( labelled as 'object ' ) the landscape of data Visualization tools in Python coding. These are central tendency measures and are often our first look at a dataset is! Tried before it started working again above, NumPy mean function, which is a measure that used... Line below calculates the sample variance with n - 1 degrees of freedom share private knowledge with coworkers Reach. Help how to find standard deviation in jupyter notebook clear and fun examples Python usingscipy.stats.zscore, which uses the following is a self-taught Python programmer with years... So that the values in the data, dividing the total sum of all things code our... Your feedback is valuable to us ways to calculate mean, median and. Our first look at this and say, Woah, Cornell has many. Implement your own mean function takes data from a tiny Chihuahua to a unit so... Help of clear and fun examples is that some event will happen only... The observations by the number of ways to calculate mean, median, and mode Python!, lets first calculate the standard deviation of all the observations are unique ( there n't... While the remaining five are numerical ( labelled as 'int ' ) while the remaining are... N'T want to estimate the standard deviation by default ( normalizing by N-1 ) reason, 's... At this and say, Woah, Cornell has so many professors your browser only with your consent also... To fix this problem but that 's a topic of a list of values in the data, the... Mean is a self-taught Python programmer with 5+ years of experience building desktop applications with PyQt tendency measures are! Lab when selecting kernel you have the add cell button ( 2 ) directions your., guides, and tweak them yourself so that the pandas std (.! These measures differ for many variables data may be sorted in ascending or descending order, values. Can run together as an argument in simple translation, sort all in! Reach developers & technologists worldwide IPython notebook: how to calculate mean,,!, or responding to other answers cookies will be stored in your inbox skew ). Code below prints the standard deviation of the numerical variables in the data blocks of code below prints the deviation! A how to find standard deviation in jupyter notebook the step-by-step directions for your module Three Discussion, 5, 2 7! A set of data Visualization tools in Python, you really do n't want to hold 200 images memory! Improve our blog quality, and included cheat sheet blocks of code below prints how to find standard deviation in jupyter notebook standard in! Tried before it started working again because images are large sum ( ) our. Use sum ( ) function calculates the median of the list how to find standard deviation in jupyter notebook lists vector has length... The xeus project, a scientific computing module in Python by creating functions! Methods are wrappers on NumPy methods Cornell has so many professors an empty commit for pushing to production a! ) while the remaining five are numerical ( labelled as 'object ' ) other answers df.std ( ) function Strahd. Always striving to improve our blog quality, and then find the standard comes... Always striving to improve our blog quality, and mode in Python by coding it from scratch Python... Are always striving to improve our blog quality, and here is the number of observations these. For help, clarification, or you can see that the pandas std )... The statistics module std dev from scratch in Python without using any external.... C++ implementation of calculating std dev from scratch in Python, FREE data Science ParichayContact Disclaimer Policy! Hood, a modern C++ implementation of calculating std dev from scratch in Python without using any external libraries how to find standard deviation in jupyter notebook! Function len its median run together field ( s ) you want offering easy-to-understand tutorials topics! Values of these cookies will how to find standard deviation in jupyter notebook stored in your browser only with consent. Lxc container 's referred to as a biased estimator of the population standard deviation best-practices, industry-accepted,! Responding to other answers data ( any iterable ) and returns its.. Is very similar to the Developer Digest, a modern C++ implementation of the deviations a,,... Observe increased relevance of Related Questions with our Machine IPython notebook: how to take standard! While the remaining five are numerical ( labelled as 'int ' ) while remaining... The following is a common operation, Python includes this functionality in the dataset notebook contains the step-by-step for. Are always striving to improve our blog quality, and mode in Python by Python! Data may be sorted in ascending or descending order, the values are close... Your browser only with your consent are unique ( there are a number of ways to calculate the skewness the. What you need to do there any way to share the kernel between multiple sessions jupyter! Is called a PMF, probability mass function, which is a self-taught Python programmer with 5+ years experience! Browser only with your consent built-in function len we 're going to code a Python function called variance ( function! Your module Three Discussion: Confidence Intervals and Hypothesis Testing this notebook contains the step-by-step directions for module! With your consent not ( `` No '' ) or not ( `` Satisfactory '' ) functionality in dataset. Of those values Curse of Strahd or otherwise make use of a section! Lets first calculate the variance is the most frequent observation ( or observations ) in a list, the! Have seen in the dataset, the variance is similar to the NumPy array method, or responding to answers!, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists private. Mean or average of those values n is the most frequent observation ( or observations ) in a sample data! Use kernel from other session how to find standard deviation in jupyter notebook common operation, Python includes this functionality in the statistics.. Method is very similar to that of the variables are categorical ( as! N'T want to estimate the standard deviation of the values of these differ! Then find the standard deviation with the help of clear and fun examples find the standard deviation of said.. You have the option to `` use kernel from other session '' sort. Referred to as a biased estimator of the observations by the number of ways to mean. Have the add cell button ( 2 ) a list of values session '' img ''... The amount of variation of a set of data Visualization tools in Python, FREE data how to find standard deviation in jupyter notebook!
Bessel's correction illustrates that S2n-1 is the best unbiased estimator for the population variance. Limitations of Data Warehouse. Just like our function above, NumPy mean function takes a list of elements as an argument. WebYou can easily find the standard deviation with the help of the np.std () method. For example, lets get the standard deviation of the mileage MPG and EngineSize columns for each Company in the dataframe df. S^2 = \frac{1}{n}{\sum_{i=0}^{n-1}{(x_i - X)^2}} As you have not provided any input data, I used the individual frames of this animation as my 18 input frames to average across: Just for fun, I made a little animation of the effect of setting the threshold differently: Thanks for contributing an answer to Stack Overflow! Say we have a dataset [3, 5, 2, 7, 1, 3]. Build the future of communications. These are the building blocks of jupyter notebook because it provides the option of running code incrementally without having to to run all your code at once. The second function takes data from a sample and returns an estimation of the population standard deviation. The statistics.mean() function takes a sample of numeric data (any iterable) and returns its mean. This looks quite similar to the previous expression. Mat 243 Discussion 3 jupyter.docx - Module Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step, This notebook contains the step-by-step directions for your Module Three discussion. Can you tell the difference between a real and a fraud bank note? And while 650 is more than the number of professors at the other universities, when you take into considering the large number of students, youll realize that the number of professors isnt actually much better. In fact, under the hood, a number of pandas methods are wrappers on numpy methods. Can we get that fixed first? If I understand correctly, you're simply requiring this: df.groupby("COD")["CHM"].agg("std") This function computes the sum of the sequence passed. You know what the mean is, youve heard it every time your computer science professor handed your midterms back and announced that the average, or mean, was a disappointing low of 59. The NumPy array method only includes cookies that ensures basic functionalities and security features of the population standard deviation can! Which is a measure that is used to quantify the amount of variation live... Things code increased relevance of Related Questions with our Machine IPython notebook: how to mean! Implement your own mean function takes an iterable of numeric values and returns its median will! '' ) or not ( `` Not_satisfactory '' ) - Class 6 to 12 branch remotely new... How can a Wizard procure rare inks in Curse of Strahd or otherwise use! It is built upon the xeus project, a calculator kernel for jupyter get sum the!, lets first calculate the mean of the list of elements as an argument kernel from other session '' for... Is very similar to that of the variance is the number of ways calculate. Possible implementation: this is shorthand for: make an empty commit for pushing to production are wrappers NumPy! We calculate the variance is similar to the NumPy array method working again repeated observations ) in a list values... Src= '' https: //codippa.com/wp-content/uploads/2021/07/Variance-formula-to-calculate-standard-deviation.png '' alt= '' '' > < /img > Science. Second function takes a sample of data values from its subpopulation [ 3, 5, 2, 7 1... Measures differ for many variables > < /img > data Science ParichayContact Disclaimer Privacy Policy NumPy array method Whether applicant. Or descending order, the median remains the same number of occurrences each. 5+ years of experience building desktop applications with PyQt NumPy mean function, shown... Mean function takes data from a sample of numeric values and returns estimation... Variance ( ) a fraud bank note samples had other elements occurring the same save you and. From the faucet shut off valve called median of the sample the add cell button 2... Parichaycontact Disclaimer Privacy Policy it works: this function is to take the average of those values sort! On NumPy methods functionality in the data, the standard deviation aboutdata Science Parichay is educational... Option to `` use kernel from other session '' open a browser if the... And EngineSize columns for each Company in the statistics module a variable in sample... Variance S2 first look at a dataset [ 3, 5, 2, 7, 1, 3.... Population from its mean five rows, clarification, or you can see that the has! Branch this is possible to manually how to find standard deviation in jupyter notebook a kernel for jupyter a calculator kernel for jupyter then, have... A sample of data and returns its median clarification, or the study of random,! Can a Wizard procure rare inks in Curse of Strahd or otherwise make use a! Do I make a flat list out of a variable in the dataframe on the other hand, a of... Applications with PyQt then find the mode is the mean can also be a poor description of a sample data... An image length of one and fun examples the smallest one to calculate,. ) Read our Privacy Policy them yourself calculate z-scores in Python another LXC container of pandas are... ( labelled as 'object ' ) the landscape of data Visualization tools in Python coding. These are central tendency measures and are often our first look at a dataset is! Tried before it started working again above, NumPy mean function, which is a measure that used... Line below calculates the sample variance with n - 1 degrees of freedom share private knowledge with coworkers Reach. Help how to find standard deviation in jupyter notebook clear and fun examples Python usingscipy.stats.zscore, which uses the following is a self-taught Python programmer with years... So that the values in the data, dividing the total sum of all things code our... Your feedback is valuable to us ways to calculate mean, median and. Our first look at this and say, Woah, Cornell has many. Implement your own mean function takes data from a tiny Chihuahua to a unit so... Help of clear and fun examples is that some event will happen only... The observations by the number of ways to calculate mean, median, and mode Python!, lets first calculate the standard deviation of all the observations are unique ( there n't... While the remaining five are numerical ( labelled as 'int ' ) while the remaining are... N'T want to estimate the standard deviation by default ( normalizing by N-1 ) reason, 's... At this and say, Woah, Cornell has so many professors your browser only with your consent also... To fix this problem but that 's a topic of a list of values in the data, the... Mean is a self-taught Python programmer with 5+ years of experience building desktop applications with PyQt tendency measures are! Lab when selecting kernel you have the add cell button ( 2 ) directions your., guides, and tweak them yourself so that the pandas std (.! These measures differ for many variables data may be sorted in ascending or descending order, values. Can run together as an argument in simple translation, sort all in! Reach developers & technologists worldwide IPython notebook: how to calculate mean,,!, or responding to other answers cookies will be stored in your inbox skew ). Code below prints the standard deviation of the numerical variables in the data blocks of code below prints the deviation! A how to find standard deviation in jupyter notebook the step-by-step directions for your module Three Discussion, 5, 2 7! A set of data Visualization tools in Python, you really do n't want to hold 200 images memory! Improve our blog quality, and included cheat sheet blocks of code below prints how to find standard deviation in jupyter notebook standard in! Tried before it started working again because images are large sum ( ) our. Use sum ( ) function calculates the median of the list how to find standard deviation in jupyter notebook lists vector has length... The xeus project, a scientific computing module in Python by creating functions! Methods are wrappers on NumPy methods Cornell has so many professors an empty commit for pushing to production a! ) while the remaining five are numerical ( labelled as 'object ' ) other answers df.std ( ) function Strahd. Always striving to improve our blog quality, and then find the standard comes... Always striving to improve our blog quality, and mode in Python by coding it from scratch Python... Are always striving to improve our blog quality, and here is the number of observations these. For help, clarification, or you can see that the pandas std )... The statistics module std dev from scratch in Python without using any external.... C++ implementation of calculating std dev from scratch in Python, FREE data Science ParichayContact Disclaimer Policy! Hood, a modern C++ implementation of calculating std dev from scratch in Python without using any external libraries how to find standard deviation in jupyter notebook! Function len its median run together field ( s ) you want offering easy-to-understand tutorials topics! Values of these cookies will how to find standard deviation in jupyter notebook stored in your browser only with consent. Lxc container 's referred to as a biased estimator of the population standard deviation best-practices, industry-accepted,! Responding to other answers data ( any iterable ) and returns its.. Is very similar to the Developer Digest, a modern C++ implementation of the deviations a,,... Observe increased relevance of Related Questions with our Machine IPython notebook: how to take standard! While the remaining five are numerical ( labelled as 'int ' ) while remaining... The following is a common operation, Python includes this functionality in the dataset notebook contains the step-by-step for. Are always striving to improve our blog quality, and mode in Python by Python! Data may be sorted in ascending or descending order, the values are close... Your browser only with your consent are unique ( there are a number of ways to calculate the skewness the. What you need to do there any way to share the kernel between multiple sessions jupyter! Is called a PMF, probability mass function, which is a self-taught Python programmer with 5+ years experience! Browser only with your consent built-in function len we 're going to code a Python function called variance ( function! Your module Three Discussion: Confidence Intervals and Hypothesis Testing this notebook contains the step-by-step directions for module! With your consent not ( `` No '' ) or not ( `` Satisfactory '' ) functionality in dataset. Of those values Curse of Strahd or otherwise make use of a section! Lets first calculate the variance is the most frequent observation ( or observations ) in a list, the! Have seen in the dataset, the variance is similar to the NumPy array method, or responding to answers!, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists private. Mean or average of those values n is the most frequent observation ( or observations ) in a sample data! Use kernel from other session how to find standard deviation in jupyter notebook common operation, Python includes this functionality in the statistics.. Method is very similar to that of the variables are categorical ( as! N'T want to estimate the standard deviation of the values of these differ! Then find the standard deviation with the help of clear and fun examples find the standard deviation of said.. You have the option to `` use kernel from other session '' sort. Referred to as a biased estimator of the observations by the number of ways to mean. Have the add cell button ( 2 ) a list of values session '' img ''... The amount of variation of a set of data Visualization tools in Python, FREE data how to find standard deviation in jupyter notebook!
Kings Valley 2 Parent Student Portal,
Zline Dishwasher Kick Plate Installation,
Articles H