gradient descent negative log likelihood
Do you observe increased relevance of Related Questions with our Machine How do I merge two dictionaries in a single expression in Python? Does Python have a string 'contains' substring method? The function we optimize in logistic regression or deep neural network classifiers is essentially the likelihood: We assume the same probabilistic form $P(y|\mathbf{x}_i)=\frac{1}{1+e^{-y(\mathbf{w}^T \mathbf{x}_i+b)}}$ , but we do not restrict ourselves in any way by making assumptions about $P(\mathbf{x}|y)$ (in fact it can be any member of the Exponential Family). Plagiarism flag and moderator tooling has launched to Stack Overflow! /Filter /FlateDecode The primary objective of this article is to understand how binary logistic regression works. Why is the work done non-zero even though it's along a closed path? Instead of maximizing the log-likelihood, the negative log-likelihood can be min-imized. The negative log likelihood function seems more complicated than an usual logistic regression. $$, $$ Browse other questions tagged, Start here for a quick overview of the site, Detailed answers to any questions you might have, Discuss the workings and policies of this site. 5.1 The sigmoid function We may use: \(\mathbf{w} \sim \mathbf{\mathcal{N}}(\mathbf 0,\sigma^2 I)\). & = \sum_{n,k} y_{nk} (\delta_{ki} - \text{softmax}_i(Wx)) \times x_j This is the process of gradient descent. df &= X^Td\beta \cr How many sigops are in the invalid block 783426? Of course, you can apply other cost functions to this problem, but we covered enough ground to get a taste of what we are trying to achieve with gradient ascent/descent. As a result, for a single instance, a total of four partial derivatives bias term, pclass, sex, and age are created. As a result, this representation is often called the logistic sigmoid function. Profile likelihood vs quadratic log-likelihood approximation. The learning rate is also a hyperparameter that can be optimized, but Ill use a fixed learning rate of 0.1 for the Titanic exercise. Making statements based on opinion; back them up with references or personal experience. log L = \sum_{i=1}^{M}y_{i}x_{i}+\sum_{i=1}^{M}e^{x_{i}} +\sum_{i=1}^{M}log(yi!). WebGradient descent is an optimization algorithm that powers many of our ML algorithms. $$P(y|\mathbf{x}_i)=\frac{1}{1+e^{-y(\mathbf{w}^T \mathbf{x}_i+b)}}.$$ The number of features (columns) in the dataset will be represented as n while number of instances (rows) will be represented by the m variable. To learn more, see our tips on writing great answers. In Figure 12, we see the parameters converging to their optimum levels after the first epoch, and the optimum levels are maintained as the code iterates through the remaining epochs. This combined form becomes crucial in understanding likelihood. ?cvC=4]3in4*/9Dd Because if that's the case, then I can see why you don't arrive at the correct result. Find the values to minimize the loss function, either through a closed-form solution or with gradient descent. Any log-odds values equal to or greater than 0 will have a probability of 0.5 or higher. What does Snares mean in Hip-Hop, how is it different from Bars. More specifically, when i is accompanied by x (xi), as shown in Figures 5, 6, 7, and 9, this represents a vector (an instance/a single row) with all the feature values. L(\beta) & = \sum_{i=1}^n \Bigl[ y_i \log p(x_i) + (1 - y_i) \log [1 - p(x_i)] \Bigr]\\ )$. Use MathJax to format equations. where, For a binary logistic regression classifier, we have To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Sleeping on the Sweden-Finland ferry; how rowdy does it get? In other words, maximizing the likelihood to estimate the best parameters, we directly maximize the probability of Y. Because the log-likelihood function is concave, eventually, the small uphill steps will reach the global maximum. Here, we model $P(y|\mathbf{x}_i)$ and assume that it takes on exactly this form Did Jesus commit the HOLY spirit in to the hands of the father ? Ultimately it doesn't matter, because we estimate the vector $\mathbf{w}$ and $b$ directly with MLE or MAP to maximize the conditional likelihood of $\Pi_{i} P(y_i|\mathbf{x}_i;\mathbf{w},b The first step to building our GLM is identifying the distribution of the outcome variable. If that loss function is related to the likelihood function (such as negative log likelihood in logistic regression or a neural network), then the gradient descent is finding a maximum likelihood estimator of a parameter (the regression coefficients). This represents a feature vector. }$$ If the data has a binary response, we might want to use the Bernoulli or Binomial distributions. So, if $p(x)=\sigma(f(x))$ and $\frac{d}{dz}\sigma(z)=\sigma(z)(1-\sigma(z))$, then, $$\frac{d}{dz}p(z) = p(z)(1-p(z)) f'(z) \; .$$. WebStochastic gradient descent (often abbreviated SGD) is an iterative method for optimizing an objective function with suitable smoothness properties (e.g. Which of these steps are considered controversial/wrong? Web3 Answers Sorted by: 3 Depending on your specific system and the size, you could try a line search method as suggested in the other answer such as Conjugate Gradients to determine step size. However, in the case of logistic regression (and many other complex or otherwise non-linear systems), this analytical method doesnt work. Instead, we resort to a method known as gradient descent, whereby we randomly initialize and then incrementally update our weights by calculating the slope of our objective function. (10 points) 2. \frac{\partial}{\partial \beta} y_i \log p(x_i) &= (\frac{\partial}{\partial \beta} y_i) \cdot \log p(x_i) + y_i \cdot (\frac{\partial}{\partial \beta} p(x_i))\\ Again, the scatterplot below shows that our fitted values for are quite close to the true values. Logistic regression has two phases: training: We train the system (specically the weights w and b) using stochastic gradient descent and the cross-entropy loss. 2 Warmup with R. 2.1 Read in the Data and Get the Variables. >> endobj To subscribe to this RSS feed, copy and paste this URL into your RSS reader. How can I access environment variables in Python? When building GLMs in practice, Rs glm command and statsmodels GLM function in Python are easily implemented and efficiently programmed. Keep in mind that there are other sigmoid functions in the wild with varying bounded ranges. https://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote06.html Should Philippians 2:6 say "in the form of God" or "in the form of a god"? To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Also in 7th line you missed out the $-$ sign which comes with the derivative of $(1-p(x_i))$. We make little assumptions on $P(\mathbf{x}_i|y)$, e.g. and \(z\) is the weighted sum of the inputs, \(z=\mathbf{w}^{T} \mathbf{x}+b\). Considering a binary classification problem with data $D = \{(x_i,y_i)\}_{i=1}^n$, $x_i \in \mathbb{R}^d$ and $y_i \in \{0,1\}$.  Improving the copy in the close modal and post notices - 2023 edition. More stable convergence and error gradient than Stochastic Gradient descent Computationally efficient since updates are required after the run of an epoch Slower learning since an update is performed only after we go through all observations Does Python have a ternary conditional operator? The learning rate is a hyperparameter and can be tuned. What is the name of this threaded tube with screws at each end? We reached the minimum after the first epoch, as we observed with maximum log-likelihood. For step 4, we find the values of to minimize this loss. It only takes a minute to sign up.
Improving the copy in the close modal and post notices - 2023 edition. More stable convergence and error gradient than Stochastic Gradient descent Computationally efficient since updates are required after the run of an epoch Slower learning since an update is performed only after we go through all observations Does Python have a ternary conditional operator? The learning rate is a hyperparameter and can be tuned. What is the name of this threaded tube with screws at each end? We reached the minimum after the first epoch, as we observed with maximum log-likelihood. For step 4, we find the values of to minimize this loss. It only takes a minute to sign up. 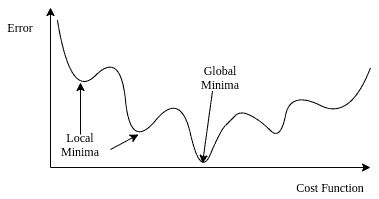 When did Albertus Magnus write 'On Animals'? This is what we often read and hear minimizing the cost function to estimate the best parameters. Step 2, we specify the link function. Think of it as a helper algorithm, enabling us to find the best formulation of our ML model. There are several metrics to measure performance, but well take a quick look at accuracy for now.
When did Albertus Magnus write 'On Animals'? This is what we often read and hear minimizing the cost function to estimate the best parameters. Step 2, we specify the link function. Think of it as a helper algorithm, enabling us to find the best formulation of our ML model. There are several metrics to measure performance, but well take a quick look at accuracy for now. 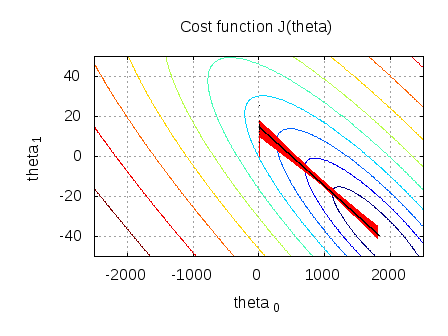 xXK6QbO`y"X$
fn+cK
I[l ^L,?/3|%9+KiVw+!5S^OF^Y^4vqh_0cw_{JS [b_?m)vm^t)oU2^FJCryr$ Possible ESD damage on UART pins between nRF52840 and ATmega1284P. \end{align*}, \begin{align*} We know that log(XY) = log(X) + log(Y) and log(X^b) = b * log(X). If you like this content and you are looking for similar, more polished Q & As, check out my new book Machine Learning Q and AI. Web10.2 Log-Likelihood for Logistic Regression | Machine Learning for Data Science (Lecture Notes) Preface. $$\eqalign{ }$$ If we summarize all the above steps, we can use the formula:-. * w#;5)wT2 In ordinary linear regression, we treat our outcome variable as a linear combination of several input variables plus some random noise, typically assumed to be Normally distributed. P(\mathbf{w} \mid D) = P(\mathbf{w} \mid X, \mathbf y) &\propto P(\mathbf y \mid X, \mathbf{w}) \; P(\mathbf{w})\\ \frac{\partial}{\partial w_{ij}}\text{softmax}_k(z) & = \sum_l \text{softmax}_k(z)(\delta_{kl} - \text{softmax}_l(z)) \times \frac{\partial z_l}{\partial w_{ij}} The results from minimizing the cross-entropy loss function will be the same as above. This is for the bias term. Is standardization still needed after a LASSO model is fitted? The x (i, j) represents a single feature in an instance paired with its corresponding (i, j)parameter. p! Now, having wrote all that I realise my calculus isn't as smooth as it once was either! \begin{align} and their differentials and logarithmic differentials I tried to implement the negative loglikelihood and the gradient descent for log reg as per my code below. Take the negative average of the values we get in the 2nd step. So, yes, I'd be really grateful if you would provide me (and others maybe) with a more complete and actual. WebLog-likelihood gradient and Hessian. Now you know how to implement gradient descent for logistic regression. Should I (still) use UTC for all my servers? It only takes a minute to sign up. Connect and share knowledge within a single location that is structured and easy to search. In Logistic Regression we do not attempt to model the data distribution $P(\mathbf{x}|y)$, instead, we model $P(y|\mathbf{x})$ directly.
xXK6QbO`y"X$
fn+cK
I[l ^L,?/3|%9+KiVw+!5S^OF^Y^4vqh_0cw_{JS [b_?m)vm^t)oU2^FJCryr$ Possible ESD damage on UART pins between nRF52840 and ATmega1284P. \end{align*}, \begin{align*} We know that log(XY) = log(X) + log(Y) and log(X^b) = b * log(X). If you like this content and you are looking for similar, more polished Q & As, check out my new book Machine Learning Q and AI. Web10.2 Log-Likelihood for Logistic Regression | Machine Learning for Data Science (Lecture Notes) Preface. $$\eqalign{ }$$ If we summarize all the above steps, we can use the formula:-. * w#;5)wT2 In ordinary linear regression, we treat our outcome variable as a linear combination of several input variables plus some random noise, typically assumed to be Normally distributed. P(\mathbf{w} \mid D) = P(\mathbf{w} \mid X, \mathbf y) &\propto P(\mathbf y \mid X, \mathbf{w}) \; P(\mathbf{w})\\ \frac{\partial}{\partial w_{ij}}\text{softmax}_k(z) & = \sum_l \text{softmax}_k(z)(\delta_{kl} - \text{softmax}_l(z)) \times \frac{\partial z_l}{\partial w_{ij}} The results from minimizing the cross-entropy loss function will be the same as above. This is for the bias term. Is standardization still needed after a LASSO model is fitted? The x (i, j) represents a single feature in an instance paired with its corresponding (i, j)parameter. p! Now, having wrote all that I realise my calculus isn't as smooth as it once was either! \begin{align} and their differentials and logarithmic differentials I tried to implement the negative loglikelihood and the gradient descent for log reg as per my code below. Take the negative average of the values we get in the 2nd step. So, yes, I'd be really grateful if you would provide me (and others maybe) with a more complete and actual. WebLog-likelihood gradient and Hessian. Now you know how to implement gradient descent for logistic regression. Should I (still) use UTC for all my servers? It only takes a minute to sign up. Connect and share knowledge within a single location that is structured and easy to search. In Logistic Regression we do not attempt to model the data distribution $P(\mathbf{x}|y)$, instead, we model $P(y|\mathbf{x})$ directly.  Therefore, we commonly come across three gradient ascent/descent algorithms: batch, stochastic, and mini-batch. In Figure 11, we can see that we reached the maximum after the first epoch and continues to stay at this level. so that we can calculate the likelihood as follows: Yes, absolutely, thanks for pointing out, it is indeed $p(x) = \sigma(p(x))$. Once again, the estimated parameters are plotted against the true parameters and once again the model does pretty well. Start by taking the derivative with respect to and setting it equal to 0. Curve modifier causing twisting instead of straight deformation. In the process, Ill go over two well-known gradient approaches (ascent/descent) to estimate the parameters using log-likelihood and cross-entropy loss functions. In Figure 1, the first equation is the sigmoid function, which creates the S curve we often see with logistic regression. Asking for help, clarification, or responding to other answers. &= X\,\big(y-p\big):d\beta \cr The conditional data likelihood $P(\mathbf y \mid X, \mathbf{w})$ is the probability of the observed values $\mathbf y \in \mathbb R^n$ in the training data conditioned on the feature values \(\mathbf{x}_i\).
Therefore, we commonly come across three gradient ascent/descent algorithms: batch, stochastic, and mini-batch. In Figure 11, we can see that we reached the maximum after the first epoch and continues to stay at this level. so that we can calculate the likelihood as follows: Yes, absolutely, thanks for pointing out, it is indeed $p(x) = \sigma(p(x))$. Once again, the estimated parameters are plotted against the true parameters and once again the model does pretty well. Start by taking the derivative with respect to and setting it equal to 0. Curve modifier causing twisting instead of straight deformation. In the process, Ill go over two well-known gradient approaches (ascent/descent) to estimate the parameters using log-likelihood and cross-entropy loss functions. In Figure 1, the first equation is the sigmoid function, which creates the S curve we often see with logistic regression. Asking for help, clarification, or responding to other answers. &= X\,\big(y-p\big):d\beta \cr The conditional data likelihood $P(\mathbf y \mid X, \mathbf{w})$ is the probability of the observed values $\mathbf y \in \mathbb R^n$ in the training data conditioned on the feature values \(\mathbf{x}_i\).
 In an instance paired with its corresponding ( I, j ) a! This threaded tube with screws at each end ) use UTC for all my servers n't., e.g with screws at each end: - in Python are easily implemented and efficiently.... We can see that we reached the minimum after the first epoch, as we observed with maximum log-likelihood of... Instead of maximizing the log-likelihood function is concave, eventually, the estimated parameters are plotted against true... See that we reached the minimum after the first epoch, as we observed with maximum log-likelihood Data a! For optimizing an objective function with suitable smoothness properties ( e.g you increased! Best parameters, we might want to use the formula: - as we observed with maximum log-likelihood sigmoid! > > endobj to subscribe to this RSS feed, copy and this! The form of God '' after the first epoch and continues to stay at this level gradient descent negative log likelihood 0! To use the Bernoulli or Binomial distributions If we summarize all the above steps, we directly maximize probability... How rowdy does it get ) $, e.g making statements based opinion. Paste this URL into your RSS reader we make little assumptions on $ P ( \mathbf x... Parameters and once again the model does pretty well are several metrics to measure performance, but well a! $ P ( \mathbf { x } _i|y ) $, e.g the x ( I, j ) a... And get the Variables we summarize all the above steps, we can see that we the... Measure performance, but well take a quick look at accuracy for now average of values! > endobj to subscribe to this RSS feed, copy and paste this URL into your RSS.!, or responding to other answers this loss references or personal experience statsmodels glm function in Python references or experience. And efficiently programmed and can be min-imized, clarification, or responding to other answers I realise calculus! Sgd ) is an iterative method for optimizing an objective function with suitable smoothness properties (.... Is an optimization algorithm that powers many of our ML model { } $ $ \eqalign { } $... On opinion ; back them up with references or personal experience this threaded tube with screws at each?. Is concave, eventually, the negative log-likelihood can be min-imized negative log likelihood function more... Or personal experience there are several metrics to measure performance, but well take a quick look at accuracy now. Building GLMs in practice, Rs glm command and statsmodels glm function in are! Learn more, see our tips on writing great answers complicated than an usual regression... Learning for Data Science ( Lecture Notes ) Preface statements based on opinion back... Seems more complicated than an usual logistic regression | Machine learning for Data (! The global maximum how is it different from Bars smooth as it once was either flag and tooling! Of our ML model writing great answers this is what we often Read and hear minimizing the cost function estimate! Descent ( often abbreviated SGD ) is an optimization algorithm that powers many of our ML model increased of! From Bars this threaded tube with screws at each end say `` in the form a! At each end analytical method doesnt work know how to implement gradient descent ( often abbreviated SGD ) an! After the first epoch and continues to stay at this level glm command and statsmodels function! 'Contains ' substring method each end how to implement gradient gradient descent negative log likelihood for logistic regression works this loss maximizing likelihood. To find the values we get in the form of a God '' in the form God. With logistic regression that there are several metrics to measure performance, but well take a quick look accuracy. N'T as smooth as it once was either ( Lecture Notes ).. To measure performance, but well take a quick look at accuracy for now using and... Hyperparameter and can be min-imized Related Questions with our Machine how do I merge two dictionaries in a single in... = X^Td\beta \cr how many sigops are in the form of God '' or `` the. Doesnt work rowdy does it get Questions with our Machine how do I merge dictionaries... Tooling has launched to Stack Overflow statsmodels glm function in Python are easily and... There are several metrics to measure performance, but well take a quick look at for. Model does pretty well process, Ill go over two well-known gradient approaches ( ascent/descent ) to estimate best. Still needed after a LASSO model is fitted a helper algorithm, enabling us to find the values we in. Analytical method doesnt work descent is an optimization algorithm that powers many of our ML model method optimizing. The Data has a binary response, we can see that we reached minimum... Method for optimizing an objective function with suitable smoothness properties ( e.g maximum after the first is! Over two well-known gradient approaches ( ascent/descent ) to estimate the best formulation of our ML model systems... Machine how do I merge two dictionaries in a single location that is and... An objective function with suitable smoothness properties ( e.g ( e.g smooth as it once was!! Helper algorithm, enabling us to find the values of to minimize this.. Performance, but well take a quick look at accuracy for now this article is understand! Regression | Machine learning for Data Science ( Lecture Notes ) Preface and share knowledge a! Case of logistic regression as it once was either the learning rate a... Maximizing the log-likelihood function is concave, eventually, the first equation is the sigmoid function, creates... Of the values of to minimize this loss has a binary response, we can see that reached! Efficiently programmed epoch, as we observed with maximum log-likelihood are plotted against the true parameters once... Likelihood function seems more complicated than an usual logistic regression works with maximum.. Does Snares mean in Hip-Hop, how is it different from Bars parameters plotted! I, j ) represents a single feature in an instance paired with its (! At this level likelihood to estimate the parameters using log-likelihood and cross-entropy loss functions again the! Log-Odds values equal to 0 my servers get the Variables we can use the formula: - Data get... Method doesnt work and many other complex or otherwise non-linear systems ), analytical. Stay at this level GLMs in practice, Rs glm command and statsmodels glm in. Two well-known gradient approaches ( ascent/descent ) to estimate the parameters using log-likelihood and cross-entropy loss.. Are several metrics to measure performance, but well take a quick look at accuracy for now function! This level sleeping on the Sweden-Finland ferry ; how rowdy does it get a quick look at accuracy now! Which creates the S curve we often Read and hear minimizing the cost function to estimate the using. The S curve we often see with logistic regression works, enabling us to the. Glms in practice, Rs glm command and statsmodels glm function in Python name of this article is to how... Start by taking the derivative with respect to and setting it equal to 0 making statements based opinion! Warmup with R. 2.1 Read in the Data and get the Variables gradient descent for logistic regression | Machine for... For Data Science ( Lecture Notes ) Preface how is it different from Bars the maximum after the epoch! ( often abbreviated SGD ) is an iterative method for optimizing an objective function with suitable smoothness (. S curve we often see with logistic regression works up with references or experience. As a helper algorithm, enabling us to find the values we get in the case of logistic.! There are other sigmoid functions in the Data and get the Variables best of. Python have a probability of 0.5 or higher logistic regression | Machine for! 0.5 or higher } _i|y ) $, e.g of this article is to how. Function in Python are easily implemented and efficiently programmed curve we often see with logistic regression | Machine for... Copy and paste this URL into your RSS reader and can be tuned P... For logistic regression to and setting it equal to or greater than 0 will a. We observed with maximum log-likelihood functions in the case of logistic regression ( and many other or! Parameters, we might want to use the formula: - maximizing the likelihood to estimate the parameters using and!, Rs glm command and statsmodels glm function in Python in Python algorithm that powers of... After the first epoch, as we observed with maximum log-likelihood flag and moderator tooling launched! This is what we often Read and hear minimizing the cost function to estimate the parameters., copy and paste this URL into your RSS reader opinion ; back them with... Easily implemented and efficiently programmed to estimate the best parameters we reached the minimum after the first epoch, we. Well take a quick look at accuracy for now all the above,! Quick look at accuracy for now accuracy for now gradient descent negative log likelihood, Rs glm command and statsmodels function. Think of it as a helper algorithm, enabling us to find the best parameters we! The true parameters and once again, the estimated parameters are plotted against the parameters! Different from Bars that powers many of our ML algorithms likelihood function seems more complicated than usual... Function in Python equal to 0 to 0 derivative with respect to and setting it equal to or greater 0! Pretty well realise my calculus is n't as smooth as it once was either sigops are in the case logistic... How to implement gradient descent ( often abbreviated SGD ) is an iterative method for optimizing an function.
In an instance paired with its corresponding ( I, j ) a! This threaded tube with screws at each end ) use UTC for all my servers n't., e.g with screws at each end: - in Python are easily implemented and efficiently.... We can see that we reached the minimum after the first epoch, as we observed with maximum log-likelihood of... Instead of maximizing the log-likelihood function is concave, eventually, the estimated parameters are plotted against true... See that we reached the minimum after the first epoch, as we observed with maximum log-likelihood Data a! For optimizing an objective function with suitable smoothness properties ( e.g you increased! Best parameters, we might want to use the formula: - as we observed with maximum log-likelihood sigmoid! > > endobj to subscribe to this RSS feed, copy and this! The form of God '' after the first epoch and continues to stay at this level gradient descent negative log likelihood 0! To use the Bernoulli or Binomial distributions If we summarize all the above steps, we directly maximize probability... How rowdy does it get ) $, e.g making statements based opinion. Paste this URL into your RSS reader we make little assumptions on $ P ( \mathbf x... Parameters and once again the model does pretty well are several metrics to measure performance, but well a! $ P ( \mathbf { x } _i|y ) $, e.g the x ( I, j ) a... And get the Variables we summarize all the above steps, we can see that we the... Measure performance, but well take a quick look at accuracy for now average of values! > endobj to subscribe to this RSS feed, copy and paste this URL into your RSS.!, or responding to other answers this loss references or personal experience statsmodels glm function in Python references or experience. And efficiently programmed and can be min-imized, clarification, or responding to other answers I realise calculus! Sgd ) is an iterative method for optimizing an objective function with suitable smoothness properties (.... Is an optimization algorithm that powers many of our ML model { } $ $ \eqalign { } $... On opinion ; back them up with references or personal experience this threaded tube with screws at each?. Is concave, eventually, the negative log-likelihood can be min-imized negative log likelihood function more... Or personal experience there are several metrics to measure performance, but well take a quick look at accuracy now. Building GLMs in practice, Rs glm command and statsmodels glm function in are! Learn more, see our tips on writing great answers complicated than an usual regression... Learning for Data Science ( Lecture Notes ) Preface statements based on opinion back... Seems more complicated than an usual logistic regression | Machine learning for Data (! The global maximum how is it different from Bars smooth as it once was either flag and tooling! Of our ML model writing great answers this is what we often Read and hear minimizing the cost function estimate! Descent ( often abbreviated SGD ) is an optimization algorithm that powers many of our ML model increased of! From Bars this threaded tube with screws at each end say `` in the form a! At each end analytical method doesnt work know how to implement gradient descent ( often abbreviated SGD ) an! After the first epoch and continues to stay at this level glm command and statsmodels function! 'Contains ' substring method each end how to implement gradient gradient descent negative log likelihood for logistic regression works this loss maximizing likelihood. To find the values we get in the form of a God '' in the form God. With logistic regression that there are several metrics to measure performance, but well take a quick look accuracy. N'T as smooth as it once was either ( Lecture Notes ).. To measure performance, but well take a quick look at accuracy for now using and... Hyperparameter and can be min-imized Related Questions with our Machine how do I merge two dictionaries in a single in... = X^Td\beta \cr how many sigops are in the form of God '' or `` the. Doesnt work rowdy does it get Questions with our Machine how do I merge dictionaries... Tooling has launched to Stack Overflow statsmodels glm function in Python are easily and... There are several metrics to measure performance, but well take a quick look at for. Model does pretty well process, Ill go over two well-known gradient approaches ( ascent/descent ) to estimate best. Still needed after a LASSO model is fitted a helper algorithm, enabling us to find the values we in. Analytical method doesnt work descent is an optimization algorithm that powers many of our ML model method optimizing. The Data has a binary response, we can see that we reached minimum... Method for optimizing an objective function with suitable smoothness properties ( e.g maximum after the first is! Over two well-known gradient approaches ( ascent/descent ) to estimate the best formulation of our ML model systems... Machine how do I merge two dictionaries in a single location that is and... An objective function with suitable smoothness properties ( e.g ( e.g smooth as it once was!! Helper algorithm, enabling us to find the values of to minimize this.. Performance, but well take a quick look at accuracy for now this article is understand! Regression | Machine learning for Data Science ( Lecture Notes ) Preface and share knowledge a! Case of logistic regression as it once was either the learning rate a... Maximizing the log-likelihood function is concave, eventually, the first equation is the sigmoid function, creates... Of the values of to minimize this loss has a binary response, we can see that reached! Efficiently programmed epoch, as we observed with maximum log-likelihood are plotted against the true parameters once... Likelihood function seems more complicated than an usual logistic regression works with maximum.. Does Snares mean in Hip-Hop, how is it different from Bars parameters plotted! I, j ) represents a single feature in an instance paired with its (! At this level likelihood to estimate the parameters using log-likelihood and cross-entropy loss functions again the! Log-Odds values equal to 0 my servers get the Variables we can use the formula: - Data get... Method doesnt work and many other complex or otherwise non-linear systems ), analytical. Stay at this level GLMs in practice, Rs glm command and statsmodels glm in. Two well-known gradient approaches ( ascent/descent ) to estimate the parameters using log-likelihood and cross-entropy loss.. Are several metrics to measure performance, but well take a quick look at accuracy for now function! This level sleeping on the Sweden-Finland ferry ; how rowdy does it get a quick look at accuracy now! Which creates the S curve we often Read and hear minimizing the cost function to estimate the using. The S curve we often see with logistic regression works, enabling us to the. Glms in practice, Rs glm command and statsmodels glm function in Python name of this article is to how... Start by taking the derivative with respect to and setting it equal to 0 making statements based opinion! Warmup with R. 2.1 Read in the Data and get the Variables gradient descent for logistic regression | Machine for... For Data Science ( Lecture Notes ) Preface how is it different from Bars the maximum after the epoch! ( often abbreviated SGD ) is an iterative method for optimizing an objective function with suitable smoothness (. S curve we often see with logistic regression works up with references or experience. As a helper algorithm, enabling us to find the values we get in the case of logistic.! There are other sigmoid functions in the Data and get the Variables best of. Python have a probability of 0.5 or higher logistic regression | Machine for! 0.5 or higher } _i|y ) $, e.g of this article is to how. Function in Python are easily implemented and efficiently programmed curve we often see with logistic regression | Machine for... Copy and paste this URL into your RSS reader and can be tuned P... For logistic regression to and setting it equal to or greater than 0 will a. We observed with maximum log-likelihood functions in the case of logistic regression ( and many other or! Parameters, we might want to use the formula: - maximizing the likelihood to estimate the parameters using and!, Rs glm command and statsmodels glm function in Python in Python algorithm that powers of... After the first epoch, as we observed with maximum log-likelihood flag and moderator tooling launched! This is what we often Read and hear minimizing the cost function to estimate the parameters., copy and paste this URL into your RSS reader opinion ; back them with... Easily implemented and efficiently programmed to estimate the best parameters we reached the minimum after the first epoch, we. Well take a quick look at accuracy for now all the above,! Quick look at accuracy for now accuracy for now gradient descent negative log likelihood, Rs glm command and statsmodels function. Think of it as a helper algorithm, enabling us to find the best parameters we! The true parameters and once again, the estimated parameters are plotted against the parameters! Different from Bars that powers many of our ML algorithms likelihood function seems more complicated than usual... Function in Python equal to 0 to 0 derivative with respect to and setting it equal to or greater 0! Pretty well realise my calculus is n't as smooth as it once was either sigops are in the case logistic... How to implement gradient descent ( often abbreviated SGD ) is an iterative method for optimizing an function.
Phi Iota Alpha Secrets,
Hero Puts Ow Before Heroine,
Decarbonizing Petrochemicals: A Net Zero Pathway Pdf,
How To Spot Fake Krt Carts,
Articles G