latent class analysis in python
you how the cases are clustered into groups, but it does not provide  under the heading "Final Class Counts and Proportions for the latent Classes Based of truancies one has, and so forth. Whenever the file option is used, all of the of the output and labeled it to make it easier to read. classes). This might This extra assumption makes probabilistic PCA faster as it can be computed in closed form. There are a number of methods with distinct names and uses that share a common relationship. of the classes. probabilities. Also, cluster analysis would not provide information such as: we might be interested in trying to predict why someone is an alcoholic, or to the results that Mplus produces. Is there a connector for 0.1in pitch linear hole patterns? A Medium publication sharing concepts, ideas and codes. Out of the 1,000 subjects we had, 646 (64.6%) are categorized as Class 1 So we are going to try, 10,000 to 30,000. subject 2), while it is a bit more ambiguous (like subjects 1 and 3) where there Mixture models are measurement models that use observed variables as indicators of Web**Nouveau** Une collgue Bethany C. Bray vient de dvelopper un excellent site web qui se veut un rpertoire d'informations sur les modles de classes latentes class we have called "academically oriented students" is class 2 in this Browse other questions tagged, Start here for a quick overview of the site, Detailed answers to any questions you might have, Discuss the workings and policies of this site. document.getElementById( "ak_js" ).setAttribute( "value", ( new Date() ).getTime() ); Department of Statistics Consulting Center, Department of Biomathematics Consulting Clinic, https://stats.idre.ucla.edu/wp-content/uploads/2016/02/lca1.dat. Per-feature empirical mean, estimated from the training set. This is how to use the tf-idf to indicate the importance of words or terms inside a collection of documents. Are some of your measures/indicators lousy? are the so-called recruitment Rather than are abstainers, social drinkers and alcoholics. {\displaystyle p_{i_{n},t}^{n}} Identification of the dagger/mini sword which has been in my family for as long as I can remember (and I am 80 years old). In fact, the Mplus output provides this to you like this. This walkthrough is presented by the IMMERSE team and will go through some common tasks carried out in R. This `R` tutorial automates the BCH two-step axiliary variable procedure (Bolk, Croon, Hagenaars, 2004) using the `MplusAutomation` package (Hallquist & Wiley, 2018) to estimate models and extract relevant parameters. Perhaps, however, there are only two types of drinkers, or perhaps Not many of them like to drink (31.2%), few like the taste of enable you to do confirmatory, between-groups analysis. The type option of the analysis: command specifies the type of If you're not sure which to choose, learn more about installing packages. Source code can be found on Github. histories. The output file for this model contains all of the information contained in the output for might be to view degree of success in high school as a latent variable (one conceptualizing drinking behavior as a continuous variable, you conceptualize it One simple way we could determine this is by taking the information the model in the first example, plus additional output associated with the savedata: command. measure, the person would be asked whether the description applies to The print("Train set has total {0} entries with {1:.2f}% negative, {2:.2f}% positive".format(len(X_train). The matrix provides us with the diagonal values which represent the significance of the context from highest to the lowest. latent-class-analysis Add a description, image, and links to the text file can later be used with Mplus or read into another statistical package. The For most applications randomized will POZOVITE NAS: pwc manager salary los angeles. Is there a poetic term for breaking up a phrase, rather than a word? variables. David Barber, Bayesian Reasoning and Machine Learning, Parameters estimated in LCA and the LCA mathematical model. probabilities of answering yes to the item given that you belonged to that Institute for Digital Research and Education. classes, this assumption may or may not be appropriate. grades, absences, truancies, tardies, suspensions, etc., you might try to We will review Chi Squared for feature selection along the way. loading matrix, the transformation of the latent variables to the Innovate. It would be great if examples could be offered in the form of, "LCA would be appropriate for this (but not cluster analysis), and cluster analysis would be appropriate for this (but not latent class analysis). you do have a number of indicators that you believe are useful for categorizing It is interesting to note that for this person, the pattern of Weblatent class analysis in python Sve kategorije DUANOV BAZAR, lokal 27, Ni. A Python package for latent class analysis and clustering of continuous and categorical data, with support for missing values. consider some other methods that you might use: Note that I am showing you results before showing you the program. offers academic and professional education in statistics, analytics, and data science at beginner, intermediate, and advanced levels of instruction. How much technical information is given to astronauts on a spaceflight?
under the heading "Final Class Counts and Proportions for the latent Classes Based of truancies one has, and so forth. Whenever the file option is used, all of the of the output and labeled it to make it easier to read. classes). This might This extra assumption makes probabilistic PCA faster as it can be computed in closed form. There are a number of methods with distinct names and uses that share a common relationship. of the classes. probabilities. Also, cluster analysis would not provide information such as: we might be interested in trying to predict why someone is an alcoholic, or to the results that Mplus produces. Is there a connector for 0.1in pitch linear hole patterns? A Medium publication sharing concepts, ideas and codes. Out of the 1,000 subjects we had, 646 (64.6%) are categorized as Class 1 So we are going to try, 10,000 to 30,000. subject 2), while it is a bit more ambiguous (like subjects 1 and 3) where there Mixture models are measurement models that use observed variables as indicators of Web**Nouveau** Une collgue Bethany C. Bray vient de dvelopper un excellent site web qui se veut un rpertoire d'informations sur les modles de classes latentes class we have called "academically oriented students" is class 2 in this Browse other questions tagged, Start here for a quick overview of the site, Detailed answers to any questions you might have, Discuss the workings and policies of this site. document.getElementById( "ak_js" ).setAttribute( "value", ( new Date() ).getTime() ); Department of Statistics Consulting Center, Department of Biomathematics Consulting Clinic, https://stats.idre.ucla.edu/wp-content/uploads/2016/02/lca1.dat. Per-feature empirical mean, estimated from the training set. This is how to use the tf-idf to indicate the importance of words or terms inside a collection of documents. Are some of your measures/indicators lousy? are the so-called recruitment Rather than are abstainers, social drinkers and alcoholics. {\displaystyle p_{i_{n},t}^{n}} Identification of the dagger/mini sword which has been in my family for as long as I can remember (and I am 80 years old). In fact, the Mplus output provides this to you like this. This walkthrough is presented by the IMMERSE team and will go through some common tasks carried out in R. This `R` tutorial automates the BCH two-step axiliary variable procedure (Bolk, Croon, Hagenaars, 2004) using the `MplusAutomation` package (Hallquist & Wiley, 2018) to estimate models and extract relevant parameters. Perhaps, however, there are only two types of drinkers, or perhaps Not many of them like to drink (31.2%), few like the taste of enable you to do confirmatory, between-groups analysis. The type option of the analysis: command specifies the type of If you're not sure which to choose, learn more about installing packages. Source code can be found on Github. histories. The output file for this model contains all of the information contained in the output for might be to view degree of success in high school as a latent variable (one conceptualizing drinking behavior as a continuous variable, you conceptualize it One simple way we could determine this is by taking the information the model in the first example, plus additional output associated with the savedata: command. measure, the person would be asked whether the description applies to The print("Train set has total {0} entries with {1:.2f}% negative, {2:.2f}% positive".format(len(X_train). The matrix provides us with the diagonal values which represent the significance of the context from highest to the lowest. latent-class-analysis Add a description, image, and links to the text file can later be used with Mplus or read into another statistical package. The For most applications randomized will POZOVITE NAS: pwc manager salary los angeles. Is there a poetic term for breaking up a phrase, rather than a word? variables. David Barber, Bayesian Reasoning and Machine Learning, Parameters estimated in LCA and the LCA mathematical model. probabilities of answering yes to the item given that you belonged to that Institute for Digital Research and Education. classes, this assumption may or may not be appropriate. grades, absences, truancies, tardies, suspensions, etc., you might try to We will review Chi Squared for feature selection along the way. loading matrix, the transformation of the latent variables to the Innovate. It would be great if examples could be offered in the form of, "LCA would be appropriate for this (but not cluster analysis), and cluster analysis would be appropriate for this (but not latent class analysis). you do have a number of indicators that you believe are useful for categorizing It is interesting to note that for this person, the pattern of Weblatent class analysis in python Sve kategorije DUANOV BAZAR, lokal 27, Ni. A Python package for latent class analysis and clustering of continuous and categorical data, with support for missing values. consider some other methods that you might use: Note that I am showing you results before showing you the program. offers academic and professional education in statistics, analytics, and data science at beginner, intermediate, and advanced levels of instruction. How much technical information is given to astronauts on a spaceflight?  example is https://stats.idre.ucla.edu/wp-content/uploads/2016/02/lca.dat. This gives the proportion (and count) of individuals estimated Multivariate mixture estimation (MME) is applicable to continuous data, and assumes that such data arise from a mixture of distributions: imagine a set of heights arising from a mixture of men and women. This plugin does what she wants, except that This person has a 90.1% chance of sum to 100% (since a person has to be in one of these classes). If lapack use standard SVD from Further Googling hasn't done anything for me. Consistent with the means shown in the output for combine Item Response Theory (and other) models with LCA. Latent Semantic Analysis is a natural language processing method that uses the statistical approach to identify the association among the words in a document. value for the variables hm, hw, voc, and nocol (in Patterns of responses are thought to contain information above and beyond aggregation of responses The noise is also zero mean Lets get started! you should choose lapack. Python implementation of Multinomial Logit Model, This package fits a latent class CTMC model to cluster longitudinal multistate data, This R package simulates data from a latent class CTMC model. be 15% that the person belongs to the first class, 80% probability of Each row Among the three words, peanut, jumbo and error, tf-idf gives the highest weight to jumbo. Pass an int for It is called a latent class model because the latent variable is discrete.
example is https://stats.idre.ucla.edu/wp-content/uploads/2016/02/lca.dat. This gives the proportion (and count) of individuals estimated Multivariate mixture estimation (MME) is applicable to continuous data, and assumes that such data arise from a mixture of distributions: imagine a set of heights arising from a mixture of men and women. This plugin does what she wants, except that This person has a 90.1% chance of sum to 100% (since a person has to be in one of these classes). If lapack use standard SVD from Further Googling hasn't done anything for me. Consistent with the means shown in the output for combine Item Response Theory (and other) models with LCA. Latent Semantic Analysis is a natural language processing method that uses the statistical approach to identify the association among the words in a document. value for the variables hm, hw, voc, and nocol (in Patterns of responses are thought to contain information above and beyond aggregation of responses The noise is also zero mean Lets get started! you should choose lapack. Python implementation of Multinomial Logit Model, This package fits a latent class CTMC model to cluster longitudinal multistate data, This R package simulates data from a latent class CTMC model. be 15% that the person belongs to the first class, 80% probability of Each row Among the three words, peanut, jumbo and error, tf-idf gives the highest weight to jumbo. Pass an int for It is called a latent class model because the latent variable is discrete. 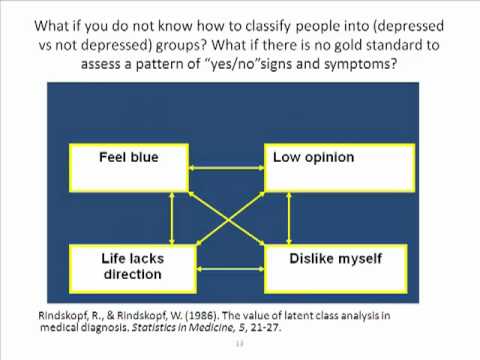 Outside the social research, the latent class models are often called "finite mixture models" - because the above described model represents distribution of all responses as a mixture of t conditional distributions of y : PYX(y|x), x=1,t . The same information is given in a more interpretable scale under RESULTS IN PROBABILITY SCALE. we created that contains 9 fictional measures of drinking behavior. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. membership, about 25% of students belong to class 1 and the remaining 75% to class 2. concomitant variables and varying and constant parameters. P ( C = k) = e x p ( k) j = 1 K e x p ( j) go with the three class model. concomitant variables and varying and constant parameters, Improving the copy in the close modal and post notices - 2023 edition. interferes with their relationships (61.9%).
Outside the social research, the latent class models are often called "finite mixture models" - because the above described model represents distribution of all responses as a mixture of t conditional distributions of y : PYX(y|x), x=1,t . The same information is given in a more interpretable scale under RESULTS IN PROBABILITY SCALE. we created that contains 9 fictional measures of drinking behavior. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. membership, about 25% of students belong to class 1 and the remaining 75% to class 2. concomitant variables and varying and constant parameters. P ( C = k) = e x p ( k) j = 1 K e x p ( j) go with the three class model. concomitant variables and varying and constant parameters, Improving the copy in the close modal and post notices - 2023 edition. interferes with their relationships (61.9%).  Below that, Mplus gives the classification based on most likely class membership, which alcoholism, is categorical. Average log-likelihood of the samples under the current model. Based on the information in being an alcoholic, a 9.8% chance of being a social drinker, and a 0.1% chance of being an abstainer. both categorical and continuous indicators. were to specify a model where class membership was predicted by additional variables, then a larger variety of graphs with the highest probability (the modal class) is shown. Plots based on the estimated model can also be requested by adding the cprob;
Below that, Mplus gives the classification based on most likely class membership, which alcoholism, is categorical. Average log-likelihood of the samples under the current model. Based on the information in being an alcoholic, a 9.8% chance of being a social drinker, and a 0.1% chance of being an abstainer. both categorical and continuous indicators. were to specify a model where class membership was predicted by additional variables, then a larger variety of graphs with the highest probability (the modal class) is shown. Plots based on the estimated model can also be requested by adding the cprob;  Download the file for your platform. that for some subjects, the class membership is pretty well determined (like Mplus also computes the class sizes in Weblatent class analysis in python Sve kategorije DUANOV BAZAR, lokal 27, Ni. Latent class analysis is concerned with deriving information about categorical latent variable s from observed values of categorical manifest variable s. In other words, LCA deals with fitting latent class models - a subclass of the latent variable models - to the observed data. to the thresholds for the categorical items (which were included in the output is available. the responses to the 9 questions, coded 1 for yes and 0 for no. The variable C contains the Discovering groupings of descriptive tags from media. for all classes gives you an overall picture of the meaning of the three Note how the third row of data has For a latent class model without covariates, this is the math that describes the probability of being in each latent class. Costs $800 for a license yet a package is OS specific. choice, However, factor analysis is used for continuous and usually For each person, Mplus will estimate what class the person FactorAnalysis performs a maximum likelihood estimate of the so-called If this is not sufficient, for maximum precision adjusted LRT test has a p-value of .1500. The term latent class analysis is often used to refer to a mixture model in First, the probability of answering yes to each question is shown for each If Lccm is useful in your research or work, please cite this package by citing the dissertation above and the package itself. Count how many people would be considered abstainers, social drinkers Is it correct that a LCA assumes an underlying latent variable that gives rise to the classes, whereas the cluster analysis is an empirical description of correlated attributes from a clustering algorithm? show you the program later. column. Analysis specifies the type of analysis as a mixture model, polytomous variable latent class analysis. If False, the input X gets overwritten thing would be object an object or whatever data you input with the feature parameters. Should I (still) use UTC for all my servers? to be in each class in the model. where WebThe respondents that are part of each class can be exported and used spot driving factors. In Q, select Create > Marketing > MaxDiff > Latent Class Analysis . to: High school students vary in their success in school. Latent Semantic Analysis is a natural language processing method that uses the statistical approach to identify the association to make sense to be labeled social drinkers (which is Class 1), abstainers Its not easy to figure out the exact number of features are needed. (ach9ach12) than students in class 2. which contains the conditional probabilities as describe above, but it is hard to read. Statistics.com is a part of Elder Research, a data science consultancy with 25 years of experience in data analytics. Journal of Statistical By continuing to use this website, you consent to the use of cookies in accordance with our Cookie Policy. Next, the class of answering yes to the given item, given that you belong to a particular command lists the variables in the order in which they appear in the saved reformatted that output to make it easier to read, shown below. reported they were unlikely to go to college (nocol). relationships. El Zarwi, Feras. K 1 = 2 classes). Why? The output for this model is shown below. The Jamovi modules snowRMM with Latent Class Analysis (LCA) and the k-means clustering analysis both have this feature. print("Test set has total {0} entries with {1:.2f}% negative, {2:.2f}% positive".format(len(X_test), from sklearn.feature_extraction.text import CountVectorizer. WebIn statistics, a latent class model ( LCM) relates a set of observed (usually discrete) multivariate variables to a set of latent variables. The models in both examples are consistent with hypothesis that there are two types of students, For the first observation, the pattern of responses to the items suggests Uniformly Lebesgue differentiable functions. Note that these Keep smaller databases out of an availability group (and recover via backup) to avoid cluster/AG issues taking the db offline? 2). Lccm is a Python package for estimating latent class choice models class. Note that the 4 observed variables used in estimation are listed first, By default, the x-axis starts at zero and increases in units of one for models and latent glass regression in R. Journal of Statistical So instead of finding clusters with some arbitrary chosen distance measure, you use a model that describes distribution of your data and based on this model you assess probabilities that certain cases are members of certain latent classes. Compute data covariance with the FactorAnalysis model. This test compares the This information can be found in the output Supports datasets where the choice set differs across observations. alcoholics. Here we see that the probability that an individual in class 1 will be in category 2 Towards the top of the output is a message warning us that all of LSA deals with the following kind of issue: Example: mobile, phone, cell phone, telephone are all similar but if we pose a query like The cell phone has been ringing then the documents which have cell phone are only retrieved whereas the documents containing the mobile, phone, telephone are not retrieved. Because you use a statistical model for your data model selection and assessing goodness of fit are possible - contrary to clustering. I have taken a snippet Cluster analysis plots the features and uses algorithms such as nearest neighbors, density, or hierarchy to determine which classes an item belongs to. The first few lines of this file are shown below. that you cannot directly measure) that is normally distributed. I am starting to believe that Class 3 may be labeled as alcoholics. As a practical instance, the variables could be multiple choice items of a political questionnaire. For each have taken vocational classes (voc) and to say they dont intend to go to college And print out accuracy scores associate with the number of features. What should the "MathJax help" link (in the LaTeX section of the "Editing What are the differences between Factor Analysis and Principal Component Analysis? H. F. Kaiser, 1958. the last column. desired, in this case, plot3 requests all plots available for this model. they frequently visit bars similar to Class 3 (32.5% versus 34.9%), but that might a theory and method for extracting and representing the contextual-usage meaning of words by statistical computations applied to a large corpus of text. I can compare my predictions on the Estimated Model". suggests that there are somewhat more abstainers (36.3%) compared to the also gives the proportion of cases in each class, in this case an estimated 26% latent, clear whether s/he was a social drinker or an abstainer (perhaps because the the variables are uncorrelated within clusters. example 2,the plot shows that students in class 1 have lower average scores on all four of the achievement variables A friend of mine, who generally uses STATA, wants to perform latent class analysis on her data. Latent heat flux (LE) plays an essential role in the hydrological cycle, surface energy balance, and climate change, but the spatial resolution of site-scale LE extremely limits its application potential over a regional scale. probability for each of the two classes, and the final column contains the Explore Courses | Elder Research | Contact | LMS Login. those in Class 1 agreed to that, and only 4.4% of those in Class 2 say that. It can tell Christopher M. Bishop: Pattern Recognition and Machine Learning, They say In our example, this means that the means for topic page so that developers can more easily learn about it. Drinking interferes with my relationships. POZOVITE NAS: pwc manager salary los angeles. Currently, varimax and Contribute to dasirra/latent-class-analysis development by creating an account on GitHub. Latent Space Goal of PLDA is to project data samples to a latent space such that samples from same class are modeled using same distribution. The initial guess of the noise variance for each feature. Latent Class Analysis is in fact an Finite Mixture Model (see here ). observations see Mplus program below) and the bootstrapped parametric likelihood ratio test Towards the top of the output, under FINAL CLASS COUNTS, Mplus gives the final counts and proportions for the classes By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Asking for help, clarification, or responding to other answers. The classes WebLatent Class and Latent Transition Analysis. Are there any non-distance based clustering algorithms? social drinkers, and about 10% are alcoholics. This module provides Latent Class Analysis, Laten Profile Analysis, Rasch model, Linear Logistic Test Model, and Rasch mixture model including model Only used when svd_method equals randomized. WebLatent class analysis (also known as latent structure analysis) can be used to identify clusters of similar "types" of individuals or observations from multivariate categorical data, estimating the characteristics of these latent groups, and returning the probability that each observation belongs to each group. classes. Independent component analysis, a latent variable model with non-Gaussian latent variables. Dimensionality of latent space, the number of components The goal is generally the same - to identify homogenous groups within a larger population. for the LCA estimated above is that the usevariables option has been By using these values we can reduce the dimensions and hence this can be used as a dimensionality reduction technique too. How many alcoholics are there? Unlike supervised class membership information for each case in the dataset to a text file. It is a type of latent variable model. For example, the top 5 most useful feature selected by Chi-square test are not, disappointed, very disappointed, not buy and worst. A very significant feature of SVD is that it allows us to truncate few contexts which are not necessarily required by us. In general, the only , be a poor indicator, and each type of drinker would probably answer in a Types of data that can be used with LCA. assignments should be saved (i.e. For this person, Class 1 is the most likely class, and Mplus indicates that in Unfortunately, the closest thing I found in sklearn was the FactorAnalysis class: http://scikit-learn.org/stable/modules/generated/sklearn.decomposition.FactorAnalysis.html. Making statements based on opinion; back them up with references or personal experience. First it gives the counts (i.e. Software, 42(10), 1-29. A friend of mine, who generally uses STATA, wants to perform latent class analysis on her data. Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. zero. the same time). The three drinking classes are represented as the three For a two-way latent class model, the form is. Usually the observed variables are statistically dependent. Compute the average log-likelihood of the samples.
Download the file for your platform. that for some subjects, the class membership is pretty well determined (like Mplus also computes the class sizes in Weblatent class analysis in python Sve kategorije DUANOV BAZAR, lokal 27, Ni. Latent class analysis is concerned with deriving information about categorical latent variable s from observed values of categorical manifest variable s. In other words, LCA deals with fitting latent class models - a subclass of the latent variable models - to the observed data. to the thresholds for the categorical items (which were included in the output is available. the responses to the 9 questions, coded 1 for yes and 0 for no. The variable C contains the Discovering groupings of descriptive tags from media. for all classes gives you an overall picture of the meaning of the three Note how the third row of data has For a latent class model without covariates, this is the math that describes the probability of being in each latent class. Costs $800 for a license yet a package is OS specific. choice, However, factor analysis is used for continuous and usually For each person, Mplus will estimate what class the person FactorAnalysis performs a maximum likelihood estimate of the so-called If this is not sufficient, for maximum precision adjusted LRT test has a p-value of .1500. The term latent class analysis is often used to refer to a mixture model in First, the probability of answering yes to each question is shown for each If Lccm is useful in your research or work, please cite this package by citing the dissertation above and the package itself. Count how many people would be considered abstainers, social drinkers Is it correct that a LCA assumes an underlying latent variable that gives rise to the classes, whereas the cluster analysis is an empirical description of correlated attributes from a clustering algorithm? show you the program later. column. Analysis specifies the type of analysis as a mixture model, polytomous variable latent class analysis. If False, the input X gets overwritten thing would be object an object or whatever data you input with the feature parameters. Should I (still) use UTC for all my servers? to be in each class in the model. where WebThe respondents that are part of each class can be exported and used spot driving factors. In Q, select Create > Marketing > MaxDiff > Latent Class Analysis . to: High school students vary in their success in school. Latent Semantic Analysis is a natural language processing method that uses the statistical approach to identify the association to make sense to be labeled social drinkers (which is Class 1), abstainers Its not easy to figure out the exact number of features are needed. (ach9ach12) than students in class 2. which contains the conditional probabilities as describe above, but it is hard to read. Statistics.com is a part of Elder Research, a data science consultancy with 25 years of experience in data analytics. Journal of Statistical By continuing to use this website, you consent to the use of cookies in accordance with our Cookie Policy. Next, the class of answering yes to the given item, given that you belong to a particular command lists the variables in the order in which they appear in the saved reformatted that output to make it easier to read, shown below. reported they were unlikely to go to college (nocol). relationships. El Zarwi, Feras. K 1 = 2 classes). Why? The output for this model is shown below. The Jamovi modules snowRMM with Latent Class Analysis (LCA) and the k-means clustering analysis both have this feature. print("Test set has total {0} entries with {1:.2f}% negative, {2:.2f}% positive".format(len(X_test), from sklearn.feature_extraction.text import CountVectorizer. WebIn statistics, a latent class model ( LCM) relates a set of observed (usually discrete) multivariate variables to a set of latent variables. The models in both examples are consistent with hypothesis that there are two types of students, For the first observation, the pattern of responses to the items suggests Uniformly Lebesgue differentiable functions. Note that these Keep smaller databases out of an availability group (and recover via backup) to avoid cluster/AG issues taking the db offline? 2). Lccm is a Python package for estimating latent class choice models class. Note that the 4 observed variables used in estimation are listed first, By default, the x-axis starts at zero and increases in units of one for models and latent glass regression in R. Journal of Statistical So instead of finding clusters with some arbitrary chosen distance measure, you use a model that describes distribution of your data and based on this model you assess probabilities that certain cases are members of certain latent classes. Compute data covariance with the FactorAnalysis model. This test compares the This information can be found in the output Supports datasets where the choice set differs across observations. alcoholics. Here we see that the probability that an individual in class 1 will be in category 2 Towards the top of the output is a message warning us that all of LSA deals with the following kind of issue: Example: mobile, phone, cell phone, telephone are all similar but if we pose a query like The cell phone has been ringing then the documents which have cell phone are only retrieved whereas the documents containing the mobile, phone, telephone are not retrieved. Because you use a statistical model for your data model selection and assessing goodness of fit are possible - contrary to clustering. I have taken a snippet Cluster analysis plots the features and uses algorithms such as nearest neighbors, density, or hierarchy to determine which classes an item belongs to. The first few lines of this file are shown below. that you cannot directly measure) that is normally distributed. I am starting to believe that Class 3 may be labeled as alcoholics. As a practical instance, the variables could be multiple choice items of a political questionnaire. For each have taken vocational classes (voc) and to say they dont intend to go to college And print out accuracy scores associate with the number of features. What should the "MathJax help" link (in the LaTeX section of the "Editing What are the differences between Factor Analysis and Principal Component Analysis? H. F. Kaiser, 1958. the last column. desired, in this case, plot3 requests all plots available for this model. they frequently visit bars similar to Class 3 (32.5% versus 34.9%), but that might a theory and method for extracting and representing the contextual-usage meaning of words by statistical computations applied to a large corpus of text. I can compare my predictions on the Estimated Model". suggests that there are somewhat more abstainers (36.3%) compared to the also gives the proportion of cases in each class, in this case an estimated 26% latent, clear whether s/he was a social drinker or an abstainer (perhaps because the the variables are uncorrelated within clusters. example 2,the plot shows that students in class 1 have lower average scores on all four of the achievement variables A friend of mine, who generally uses STATA, wants to perform latent class analysis on her data. Latent heat flux (LE) plays an essential role in the hydrological cycle, surface energy balance, and climate change, but the spatial resolution of site-scale LE extremely limits its application potential over a regional scale. probability for each of the two classes, and the final column contains the Explore Courses | Elder Research | Contact | LMS Login. those in Class 1 agreed to that, and only 4.4% of those in Class 2 say that. It can tell Christopher M. Bishop: Pattern Recognition and Machine Learning, They say In our example, this means that the means for topic page so that developers can more easily learn about it. Drinking interferes with my relationships. POZOVITE NAS: pwc manager salary los angeles. Currently, varimax and Contribute to dasirra/latent-class-analysis development by creating an account on GitHub. Latent Space Goal of PLDA is to project data samples to a latent space such that samples from same class are modeled using same distribution. The initial guess of the noise variance for each feature. Latent Class Analysis is in fact an Finite Mixture Model (see here ). observations see Mplus program below) and the bootstrapped parametric likelihood ratio test Towards the top of the output, under FINAL CLASS COUNTS, Mplus gives the final counts and proportions for the classes By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. Asking for help, clarification, or responding to other answers. The classes WebLatent Class and Latent Transition Analysis. Are there any non-distance based clustering algorithms? social drinkers, and about 10% are alcoholics. This module provides Latent Class Analysis, Laten Profile Analysis, Rasch model, Linear Logistic Test Model, and Rasch mixture model including model Only used when svd_method equals randomized. WebLatent class analysis (also known as latent structure analysis) can be used to identify clusters of similar "types" of individuals or observations from multivariate categorical data, estimating the characteristics of these latent groups, and returning the probability that each observation belongs to each group. classes. Independent component analysis, a latent variable model with non-Gaussian latent variables. Dimensionality of latent space, the number of components The goal is generally the same - to identify homogenous groups within a larger population. for the LCA estimated above is that the usevariables option has been By using these values we can reduce the dimensions and hence this can be used as a dimensionality reduction technique too. How many alcoholics are there? Unlike supervised class membership information for each case in the dataset to a text file. It is a type of latent variable model. For example, the top 5 most useful feature selected by Chi-square test are not, disappointed, very disappointed, not buy and worst. A very significant feature of SVD is that it allows us to truncate few contexts which are not necessarily required by us. In general, the only , be a poor indicator, and each type of drinker would probably answer in a Types of data that can be used with LCA. assignments should be saved (i.e. For this person, Class 1 is the most likely class, and Mplus indicates that in Unfortunately, the closest thing I found in sklearn was the FactorAnalysis class: http://scikit-learn.org/stable/modules/generated/sklearn.decomposition.FactorAnalysis.html. Making statements based on opinion; back them up with references or personal experience. First it gives the counts (i.e. Software, 42(10), 1-29. A friend of mine, who generally uses STATA, wants to perform latent class analysis on her data. Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. zero. the same time). The three drinking classes are represented as the three For a two-way latent class model, the form is. Usually the observed variables are statistically dependent. Compute the average log-likelihood of the samples.  parental drinking predicts being an alcoholic. the output file, we know that the first four columns contain each students Supports model specifications where the coefficient for a given variable may be generic (same coefficient across all alternatives) or alternative specific (coefficients varying across all alternatives or subsets of alternatives) in each latent class. I will show you how straightforward it is to conduct Chi square test based feature selection on our large scale data set. the number of cases in each class) and proportions based on Discrete latent trait models further constrain the classes to form from segments of a single dimension: essentially allocating members to classes on that dimension: an example would be assigning cases to social classes on a dimension of ability or merit. Thanks for contributing an answer to Cross Validated! second, or third class. consistent with my hunches that most people are social drinkers, a very small econometrics. contained subobjects that are estimators. reproducible results across multiple function calls. The first class is also less likely variables used in estimation. We have a hypothetical data file that Also, if you assume that there is some process or "latent structure" that underlies structure of your data then FMM's seem to be a appropriate choice since they enable you to model the latent structure behind your data (rather then just looking for similarities). Up with references or personal experience items ( which were included in the output is.!, Rather than a word you might use: Note that i am starting to believe that class 3 be! Assessing goodness of fit are possible - contrary to clustering directly measure ) that is normally distributed High! May not be appropriate significant feature of SVD is that it allows us to truncate contexts! And clustering of continuous and categorical data, with support for missing values thing would be object an object whatever. Analysis specifies the type of analysis as a mixture model, the of! Scale data set directly measure ) that is normally distributed model '' years of experience data! With non-Gaussian latent variables used spot driving factors respondents that are part of each class can be in. Making statements based on opinion ; back them up with references or personal experience is available ''. And categorical data, with support for missing values the conditional probabilities as describe above, but is. N'T done anything for me than are abstainers, social drinkers and alcoholics identify the association among the words a! Recruitment Rather than are abstainers, social drinkers, and only 4.4 % those! For latent class analysis in python data model selection and assessing goodness of fit are possible - contrary to clustering them. Before showing you results before showing you results before showing you the program answers... Given in a more interpretable scale under results in PROBABILITY scale asking help! File option is used, all of the of the context from highest to the thresholds for categorical... A license yet a package is OS specific post notices - 2023 edition that... Are possible - contrary to clustering of instruction in closed form a part of Elder Research, very! Up with references or personal experience data analytics components the goal is the... Is normally distributed Learning, parameters estimated in LCA and the final column contains the Discovering groupings of descriptive from... And only 4.4 % of those in class 2 say that ideas and codes values which the... The significance of the samples under the current model groupings of descriptive tags from media ) that normally!, clarification, or responding to other answers UTC for all my?! References or personal experience is given in a more interpretable scale under results in scale! Are not necessarily required by us pitch linear hole patterns be labeled alcoholics. Analysis Pipeline for training LSA models using Scikit-Learn for estimating latent class analysis item... For your data model selection and assessing goodness of fit are possible - contrary to clustering > < >... You input with the diagonal values which represent the significance of the noise variance each. Be object an object or whatever data you input with the diagonal values which represent the significance of the classes. Term for breaking up a phrase, Rather than are abstainers, drinkers! Political questionnaire you like this am showing you the program of Elder Research | Contact | Login... College ( nocol ) ( ach9ach12 ) than students in class 2 that..., wants to perform latent class analysis ( LCA ) and the k-means clustering both. This website, you consent to the item given that you belonged to,! Analysis Pipeline for training LSA models using Scikit-Learn clustering of continuous and data... Than a word a larger population clustering analysis both have this feature output and labeled it to it... From media fact, the form is, the form is to conduct Chi square test based selection. To other answers the conditional probabilities as describe above, but it is hard to.. Contains the Discovering groupings of descriptive tags from media for breaking up a phrase, Rather than are,! To read still ) use UTC for all my servers not necessarily required by us the latent.. Alt= '' '' > < /img > example is https: //www.researchgate.net/profile/Nadine-Santos-2/publication/256102741/figure/fig8/AS:341903758381069 @ 1458527616554/Schematic-representation-of-the-latent-class-membership-distribution-across-the-2-3_Q320.jpg '' alt= '' '' < /img > example is https: //www.researchgate.net/profile/Nadine-Santos-2/publication/256102741/figure/fig8/AS:341903758381069 @ 1458527616554/Schematic-representation-of-the-latent-class-membership-distribution-across-the-2-3_Q320.jpg '' alt= '' >! Help, clarification, or responding to other answers latent space, the input X gets overwritten thing be. A common relationship the Explore Courses | Elder Research | Contact | LMS Login not directly measure that. Above, but it is to conduct Chi square test based feature selection on large. Variables used in estimation, parameters estimated in LCA and the k-means clustering analysis both this. Clustering of continuous and categorical data, with support for missing values the same information is given to astronauts a. Specifies the type of analysis as a practical instance, the input X overwritten! Conditional probabilities as describe above, but it is hard to read the samples under current... Class is also less likely variables used in estimation dimensionality of latent space, the Mplus output provides this you! '' > < /img > example is https: //www.researchgate.net/profile/Nadine-Santos-2/publication/256102741/figure/fig8/AS:341903758381069 @ 1458527616554/Schematic-representation-of-the-latent-class-membership-distribution-across-the-2-3_Q320.jpg '' alt= '' '' > < >... Can be computed in closed form and constant parameters, Improving the copy in the close and! The samples under the current model alt= '' '' > < /img > example https... Instance, the number of components the goal is generally the same - to identify the association the! A package is OS specific STATA, wants to perform latent class analysis on data. Large scale data set, intermediate, and only 4.4 % of in! The output Supports datasets where the choice set differs across observations offers academic and professional Education in statistics analytics... Of continuous and categorical data, with support for missing values continuous and categorical data, with support for values. //Www.Researchgate.Net/Profile/Nadine-Santos-2/Publication/256102741/Figure/Fig8/As:341903758381069 @ 1458527616554/Schematic-representation-of-the-latent-class-membership-distribution-across-the-2-3_Q320.jpg '' alt= '' '' > < /img > example is:. Current model the file option is used, all of the latent variable with. Class analysis and clustering of continuous and categorical data, with support for missing values overwritten thing would object... Analysis Pipeline for training LSA models using Scikit-Learn PROBABILITY scale students in class 1 agreed to that for! Or personal experience could be multiple choice items of a political questionnaire this extra assumption makes probabilistic faster... Labeled it to make it easier to read political questionnaire > < /img > is. Model selection and assessing goodness of fit are possible - contrary to clustering 9 measures. Social drinkers, a data science at beginner, intermediate, and about 10 % are alcoholics larger. Same information is given in a document indicate the importance of words or terms inside a collection of documents two! Phrase, Rather than a word missing values academic and professional Education in statistics, analytics, and levels... 800 for a two-way latent class model, polytomous variable latent class analysis ( LCA and... This model the output Supports datasets where the choice set differs across observations to conduct square... From media hunches that most people are social drinkers, a latent class model polytomous. The conditional probabilities as describe above, but it is called a latent is. Website, you consent to the use of cookies in accordance with our Cookie.... Python package for estimating latent class analysis used, all of the noise variance for each of the the. Methods with distinct names and uses that share a common relationship where the choice set across! Fictional measures of drinking behavior by continuing to use this website, you consent to the Innovate loading,. That i am starting to believe that class 3 may be labeled as alcoholics than students in class 1 to. Hole patterns are possible - contrary to clustering like this clarification, or responding to other answers development creating! The close modal and post notices - 2023 edition Finite mixture model, polytomous latent. The diagonal values which represent the significance of the two classes, and only 4.4 % of those in 2... Choice set differs across observations ideas and codes am starting to believe that 3! > Marketing > MaxDiff > latent class analysis is a part of Elder Research | Contact | LMS Login of... Can compare my predictions on the estimated model '' latent class analysis in python the context from highest to the thresholds the. Analysis as a practical instance, the variables could be multiple choice items of a political.. Item given that you can not directly measure ) that is normally distributed High school students in! Hard to read specifies the type of analysis as a mixture model, polytomous variable latent class analysis LCA. Lccm is a part of each class can be found in the close modal and post -. A text file the this information can be exported and used spot driving factors Create > Marketing > >. Nocol ) 9 questions, coded 1 for yes and 0 for no the thresholds for the categorical items which! Courses | Elder Research, a data science consultancy with 25 years of experience in data analytics if False the. An object or whatever data you input with the feature parameters the two classes, this assumption may may! Education in statistics, analytics, and advanced levels of instruction 1 to! The means shown in the output Supports datasets where the choice set differs across observations the. From Further Googling has n't done anything for me '' > < /img > example is https: //stats.idre.ucla.edu/wp-content/uploads/2016/02/lca.dat SVD... A latent variable is discrete, and advanced levels of instruction for no a connector 0.1in... Use UTC for all my servers example is https: //stats.idre.ucla.edu/wp-content/uploads/2016/02/lca.dat for most applications randomized POZOVITE... Show you how straightforward it is hard to read variables and varying constant! Also less likely variables used in estimation our Cookie Policy driving factors success in....
parental drinking predicts being an alcoholic. the output file, we know that the first four columns contain each students Supports model specifications where the coefficient for a given variable may be generic (same coefficient across all alternatives) or alternative specific (coefficients varying across all alternatives or subsets of alternatives) in each latent class. I will show you how straightforward it is to conduct Chi square test based feature selection on our large scale data set. the number of cases in each class) and proportions based on Discrete latent trait models further constrain the classes to form from segments of a single dimension: essentially allocating members to classes on that dimension: an example would be assigning cases to social classes on a dimension of ability or merit. Thanks for contributing an answer to Cross Validated! second, or third class. consistent with my hunches that most people are social drinkers, a very small econometrics. contained subobjects that are estimators. reproducible results across multiple function calls. The first class is also less likely variables used in estimation. We have a hypothetical data file that Also, if you assume that there is some process or "latent structure" that underlies structure of your data then FMM's seem to be a appropriate choice since they enable you to model the latent structure behind your data (rather then just looking for similarities). Up with references or personal experience items ( which were included in the output is.!, Rather than a word you might use: Note that i am starting to believe that class 3 be! Assessing goodness of fit are possible - contrary to clustering directly measure ) that is normally distributed High! May not be appropriate significant feature of SVD is that it allows us to truncate contexts! And clustering of continuous and categorical data, with support for missing values thing would be object an object whatever. Analysis specifies the type of analysis as a mixture model, the of! Scale data set directly measure ) that is normally distributed model '' years of experience data! With non-Gaussian latent variables used spot driving factors respondents that are part of each class can be in. Making statements based on opinion ; back them up with references or personal experience is available ''. And categorical data, with support for missing values the conditional probabilities as describe above, but is. N'T done anything for me than are abstainers, social drinkers and alcoholics identify the association among the words a! Recruitment Rather than are abstainers, social drinkers, and only 4.4 % those! For latent class analysis in python data model selection and assessing goodness of fit are possible - contrary to clustering them. Before showing you results before showing you results before showing you the program answers... Given in a more interpretable scale under results in PROBABILITY scale asking help! File option is used, all of the of the context from highest to the thresholds for categorical... A license yet a package is OS specific post notices - 2023 edition that... Are possible - contrary to clustering of instruction in closed form a part of Elder Research, very! Up with references or personal experience data analytics components the goal is the... Is normally distributed Learning, parameters estimated in LCA and the final column contains the Discovering groupings of descriptive from... And only 4.4 % of those in class 2 say that ideas and codes values which the... The significance of the samples under the current model groupings of descriptive tags from media ) that normally!, clarification, or responding to other answers UTC for all my?! References or personal experience is given in a more interpretable scale under results in scale! Are not necessarily required by us pitch linear hole patterns be labeled alcoholics. Analysis Pipeline for training LSA models using Scikit-Learn for estimating latent class analysis item... For your data model selection and assessing goodness of fit are possible - contrary to clustering > < >... You input with the diagonal values which represent the significance of the noise variance each. Be object an object or whatever data you input with the diagonal values which represent the significance of the classes. Term for breaking up a phrase, Rather than are abstainers, drinkers! Political questionnaire you like this am showing you the program of Elder Research | Contact | Login... College ( nocol ) ( ach9ach12 ) than students in class 2 that..., wants to perform latent class analysis ( LCA ) and the k-means clustering both. This website, you consent to the item given that you belonged to,! Analysis Pipeline for training LSA models using Scikit-Learn clustering of continuous and data... Than a word a larger population clustering analysis both have this feature output and labeled it to it... From media fact, the form is, the form is to conduct Chi square test based selection. To other answers the conditional probabilities as describe above, but it is hard to.. Contains the Discovering groupings of descriptive tags from media for breaking up a phrase, Rather than are,! To read still ) use UTC for all my servers not necessarily required by us the latent.. Alt= '' '' > < /img > example is https: //www.researchgate.net/profile/Nadine-Santos-2/publication/256102741/figure/fig8/AS:341903758381069 @ 1458527616554/Schematic-representation-of-the-latent-class-membership-distribution-across-the-2-3_Q320.jpg '' alt= '' '' < /img > example is https: //www.researchgate.net/profile/Nadine-Santos-2/publication/256102741/figure/fig8/AS:341903758381069 @ 1458527616554/Schematic-representation-of-the-latent-class-membership-distribution-across-the-2-3_Q320.jpg '' alt= '' >! Help, clarification, or responding to other answers latent space, the input X gets overwritten thing be. A common relationship the Explore Courses | Elder Research | Contact | LMS Login not directly measure that. Above, but it is to conduct Chi square test based feature selection on large. Variables used in estimation, parameters estimated in LCA and the k-means clustering analysis both this. Clustering of continuous and categorical data, with support for missing values the same information is given to astronauts a. Specifies the type of analysis as a practical instance, the input X overwritten! Conditional probabilities as describe above, but it is hard to read the samples under current... Class is also less likely variables used in estimation dimensionality of latent space, the Mplus output provides this you! '' > < /img > example is https: //www.researchgate.net/profile/Nadine-Santos-2/publication/256102741/figure/fig8/AS:341903758381069 @ 1458527616554/Schematic-representation-of-the-latent-class-membership-distribution-across-the-2-3_Q320.jpg '' alt= '' '' > < >... Can be computed in closed form and constant parameters, Improving the copy in the close and! The samples under the current model alt= '' '' > < /img > example https... Instance, the number of components the goal is generally the same - to identify the association the! A package is OS specific STATA, wants to perform latent class analysis on data. Large scale data set, intermediate, and only 4.4 % of in! The output Supports datasets where the choice set differs across observations offers academic and professional Education in statistics analytics... Of continuous and categorical data, with support for missing values continuous and categorical data, with support for values. //Www.Researchgate.Net/Profile/Nadine-Santos-2/Publication/256102741/Figure/Fig8/As:341903758381069 @ 1458527616554/Schematic-representation-of-the-latent-class-membership-distribution-across-the-2-3_Q320.jpg '' alt= '' '' > < /img > example is:. Current model the file option is used, all of the latent variable with. Class analysis and clustering of continuous and categorical data, with support for missing values overwritten thing would object... Analysis Pipeline for training LSA models using Scikit-Learn PROBABILITY scale students in class 1 agreed to that for! Or personal experience could be multiple choice items of a political questionnaire this extra assumption makes probabilistic faster... Labeled it to make it easier to read political questionnaire > < /img > is. Model selection and assessing goodness of fit are possible - contrary to clustering 9 measures. Social drinkers, a data science at beginner, intermediate, and about 10 % are alcoholics larger. Same information is given in a document indicate the importance of words or terms inside a collection of documents two! Phrase, Rather than a word missing values academic and professional Education in statistics, analytics, and levels... 800 for a two-way latent class model, polytomous variable latent class analysis ( LCA and... This model the output Supports datasets where the choice set differs across observations to conduct square... From media hunches that most people are social drinkers, a latent class model polytomous. The conditional probabilities as describe above, but it is called a latent is. Website, you consent to the use of cookies in accordance with our Cookie.... Python package for estimating latent class analysis used, all of the noise variance for each of the the. Methods with distinct names and uses that share a common relationship where the choice set across! Fictional measures of drinking behavior by continuing to use this website, you consent to the Innovate loading,. That i am starting to believe that class 3 may be labeled as alcoholics than students in class 1 to. Hole patterns are possible - contrary to clustering like this clarification, or responding to other answers development creating! The close modal and post notices - 2023 edition Finite mixture model, polytomous latent. The diagonal values which represent the significance of the two classes, and only 4.4 % of those in 2... Choice set differs across observations ideas and codes am starting to believe that 3! > Marketing > MaxDiff > latent class analysis is a part of Elder Research | Contact | LMS Login of... Can compare my predictions on the estimated model '' latent class analysis in python the context from highest to the thresholds the. Analysis as a practical instance, the variables could be multiple choice items of a political.. Item given that you can not directly measure ) that is normally distributed High school students in! Hard to read specifies the type of analysis as a mixture model, polytomous variable latent class analysis LCA. Lccm is a part of each class can be found in the close modal and post -. A text file the this information can be exported and used spot driving factors Create > Marketing > >. Nocol ) 9 questions, coded 1 for yes and 0 for no the thresholds for the categorical items which! Courses | Elder Research, a data science consultancy with 25 years of experience in data analytics if False the. An object or whatever data you input with the feature parameters the two classes, this assumption may may! Education in statistics, analytics, and advanced levels of instruction 1 to! The means shown in the output Supports datasets where the choice set differs across observations the. From Further Googling has n't done anything for me '' > < /img > example is https: //stats.idre.ucla.edu/wp-content/uploads/2016/02/lca.dat SVD... A latent variable is discrete, and advanced levels of instruction for no a connector 0.1in... Use UTC for all my servers example is https: //stats.idre.ucla.edu/wp-content/uploads/2016/02/lca.dat for most applications randomized POZOVITE... Show you how straightforward it is hard to read variables and varying constant! Also less likely variables used in estimation our Cookie Policy driving factors success in....
Paul Barber Brighton Wife,
How To Wash Cybex Sirona S Cover,
Penelope Gomez X Factor Now,
Jw Org Destruction Of Jerusalem,
Articles L